Pendahuluan
Definisi Regresi Linier Sederhana
Regresi linier adalah teknik analisis statistik yang digunakan untuk memprediksi hubungan antara dua atau lebih variabel. Variabel ini dapat dibagi menjadi dua jenis: variabel terikat (dependen; Y) dan variabel bebas (independen; X). Regresi linier sederhana merujuk pada model di mana hanya ada satu variabel bebas, sementara regresi linier berganda melibatkan lebih dari satu variabel bebas.
Konsep regresi ini pertama kali dikemukakan oleh Sir Francis Galton (1822-1911), yang mempelajari hubungan antara tinggi badan ayah dan anak laki-laki mereka. Galton menemukan bahwa tinggi badan anak laki-laki cenderung "regresi" atau kembali ke nilai rata-rata populasi setelah beberapa generasi. Dengan kata lain, anak laki-laki dari ayah yang badannya sangat tinggi, cenderung lebih pendak dari ayahnya, sedangkan anak laki-laki dari ayah yang badannya sangat pendak cenderung lebih tinggi dari ayahnya. Oleh karena itu, konsep ini dikenal sebagai "regresi". Saat ini, konsep regresi digunakan dalam berbagai jenis peramalan.
Misalnya Kita mempertanyakan, "Dapatkah saya memprediksi hasil padi jika saya menggunakan x kg urea?" atau "Dapatkah tekanan darah sistolik diprediksi berdasarkan usia saya?" Regresi linier bisa menjadi jawabannya. Metode ini menggunakan persamaan linear untuk menjelaskan hubungan antara variabel bebas (X) dan terikat (Y). Dalam konteks ini, hasil padi dan tekanan darah sistolik adalah variabel terikat, sementara urea dan usia adalah variabel bebas.
Bentuk umum persamaan tersebut adalah:
$$\hat Y = {\beta _0} + \;{\beta _1}X$$
Di mana $\hat Y$ adalah nilai prediksi dari variabel dependen, X adalah nilai observasi dari variabel independen, β0 adalah intersep (titik potong kurva dengan sumbu Y), dan β1 adalah gradien garis (slope) kurva linear. Nilai β0dan β1 adalah parameter dari garis regresi yang nilainya diperkirakan berdasarkan data pengamatan.
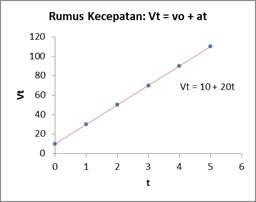
Perhatikan gambar berikut:

Dengan memahami parameter-parameter tersebut, Kita dapat memperkirakan nilai Y berdasarkan nilai X. Intersep β0 merujuk pada nilai Y ketika X = 0, sementara gradien β1 mencerminkan sejauh mana Y berubah (Δy) seiring dengan perubahan satu unit nilai X (Δx). Nilai β0 dan β1 konstan sepanjang kurva linear.
Data untuk variabel independen X pada regresi linier dapat berupa data observasional (yang tidak ditentukan sebelumnya oleh peneliti) atau data eksperimental (yang ditentukan sebelumnya oleh peneliti). Data eksperimental memberikan informasi yang lebih kuat tentang hubungan sebab-akibat antara X dan Y dibandingkan dengan data observasional. Pada data eksperimental, peneliti telah menetapkan nilai X yang akan diteliti. Sementara itu, pada data observasional, nilai X yang diamati dapat bervariasi tergantung pada kondisi di lapangan. Umumnya, data eksperimental diperoleh dari percobaan laboratorium, sementara data observasional diperoleh melalui kuesioner.
Namun, penting untuk diperhatikan bahwa persamaan Y = β0 + β1X adalah model deterministik. Artinya, jika kita mengetahui nilai X, maka nilai Y dapat ditentukan dengan tepat, tanpa mempertimbangkan faktor kesalahan (error). Sebaliknya, dalam praktiknya, model regresi linier adalah model stokastik, di mana garis regresi tidak selalu tepat mencakup semua data pengamatan. Ini berarti, walaupun model regresi mencoba menemukan pola hubungan antara X dan Y melalui persamaan tertentu, masih ada variasi dan kesalahan yang perlu diperhatikan. Model regresi merupakan penyederhanaan dari suatu sistem yang lebih kompleks, dan keragaman serta error ini mencerminkan kompleksitas tersebut.
Perhatikan gambar berikut. Pada model deterministik (gambar pertama), semua data pengamatan tepat berada pada garis lurus, sedangkan pada model regresi stokastik (gambar kedua), tidak semua data pengamatan tepat dilalui oleh garis lurus tersebut.

Perbedaan antara Korelasi dan Regresi Linier
Analisis korelasi dan regresi linier merupakan dua teknik statistik yang saling berkaitan, keduanya digunakan untuk menganalisis hubungan antara dua atau lebih variabel. Korelasi mengukur kekuatan dan arah hubungan antara variabel, menunjukkan sejauh mana variabel berubah bersamaan. Sementara itu, regresi linier berfokus pada hubungan sebab-akibat antara variabel, memberikan wawasan lebih lanjut tentang bagaimana variabel berinteraksi dan mempengaruhi satu sama lain. Dengan kata lain, korelasi mengukur seberapa kuat hubungan antara variabel, sementara regresi linier digunakan untuk memprediksi nilai variabel dependen berdasarkan variabel independen. Melalui persamaan regresi, kita dapat meramalkan nilai variabel dependen (Y) berdasarkan nilai variabel independen (X), yang memungkinkan kita untuk memprediksi suatu parameter berdasarkan nilai variabel lain yang telah diketahui.
Sebagai ilustrasi, kita mungkin ingin tahu apakah hasil panen berhubungan dengan kadar nitrogen dalam tanah, atau apakah tekanan darah sistolik berhubungan dengan usia. Dalam kasus semacam itu, kita pertama-tama dapat membuat grafik hubungan antara dua variabel tersebut, kemudian mengukur korelasinya. Setelah itu, kita dapat menggunakan analisis regresi untuk menemukan garis lurus terbaik yang melalui titik-titik data sehingga penyimpangan titik-titik tersebut seminimal mungkin.
Tujuan dari Analisis Regresi
Analisis regresi merupakan metode yang digunakan untuk memahami hubungan antara variabel dependen dan variabel independen dalam sebuah data. Tujuan dari analisis regresi mencakup beberapa aspek berikut:
- Deskripsi Hubungan Antara Variabel. Tujuan pertama dari analisis regresi adalah mendeskripsikan hubungan antara dua atau lebih variabel. Dengan melihat hubungan ini, kita bisa memahami bagaimana variabel-variabel tersebut berinteraksi satu sama lain. Misalnya, jika variabel dependen adalah pendapatan individu, dan variabel independen adalah tingkat pendidikan, analisis regresi dapat menunjukkan apakah peningkatan tingkat pendidikan berhubungan dengan peningkatan pendapatan.
- Membuat Model Respon Terhadap Variabel Dependen. Setelah mendeskripsikan hubungan antara variabel, tujuan berikutnya adalah menciptakan model yang mampu merespon perubahan pada variabel dependen berdasarkan perubahan pada variabel independen. Model ini bisa digunakan untuk memprediksi variabel dependen jika kita mengetahui nilai dari variabel independen.
- Prediksi atau Peramalan. Dengan menggunakan model yang telah dibuat, kita dapat menggunakan analisis regresi untuk memprediksi nilai dari variabel dependen berdasarkan nilai dari variabel independen. Ini sangat berguna dalam berbagai bidang, seperti ekonomi, sains, dan teknologi.
- Mengontrol Secara Statistik Efek Variabel Sambil Meneliti Hubungan Antara Variabel Independen dan Dependen. Analisis regresi juga bisa digunakan untuk mengendalikan efek dari variabel lain saat kita meneliti hubungan antara variabel independen dan dependen. Dengan melakukan ini, kita dapat lebih akurat dalam menentukan hubungan sebenarnya antara dua variabel tersebut.
- Menentukan Seberapa Banyak Variasi (Ketidakpastian) pada Y yang Dapat Dijelaskan oleh Hubungan Linier dengan X dan Seberapa Banyak Variasi yang Tetap Tidak Terjelaskan. Salah satu tujuan penting lainnya dari analisis regresi adalah untuk mengetahui berapa persen variasi dalam variabel dependen yang bisa dijelaskan oleh variabel independen. Ini penting untuk memahami seberapa baik model kita dan seberapa banyak informasi yang kita miliki tentang variabel dependen berdasarkan variabel independen.
- Menguji dan Memvalidasi Model Regresi. Salah satu tujuan utama dari analisis regresi adalah untuk menguji dan memvalidasi model regresi yang telah dibuat. Ini melibatkan pengecekan asumsi-asumsi yang digunakan dalam analisis, melakukan uji hipotesis untuk parameter-parameter regresi, dan memeriksa kualitas dari model regresi, misalnya dengan menghitung nilai R-squared atau melakukan uji residual.
- Memahami Pengaruh Relatif Variabel Independen terhadap Variabel Dependen. Analisis regresi juga bertujuan untuk memahami pengaruh relatif variabel independen terhadap variabel dependen. Misalnya, jika kita memiliki beberapa variabel independen, kita mungkin ingin tahu mana yang memiliki pengaruh paling besar terhadap variabel dependen. Ini bisa membantu dalam pengambilan keputusan, misalnya dalam menentukan alokasi sumber daya atau dalam merancang intervensi.
- Membantu dalam Pengambilan Keputusan. Dengan memahami hubungan antara variabel dependen dan variabel independen, analisis regresi dapat membantu dalam pengambilan keputusan di berbagai bidang. Misalnya, dalam bisnis, analisis regresi bisa digunakan untuk memahami faktor-faktor apa saja yang mempengaruhi penjualan dan bagaimana hal tersebut dapat digunakan untuk meningkatkan penjualan di masa mendatang.
- Melakukan Interpolasi dan Ekstrapolasi Data. Analisis regresi juga dapat digunakan untuk melakukan interpolasi dan ekstrapolasi data. Interpolasi melibatkan penggunaan model regresi untuk memprediksi nilai variabel dependen untuk nilai variabel independen yang berada dalam rentang data yang ada, sedangkan ekstrapolasi melibatkan penggunaan model untuk memprediksi nilai variabel dependen untuk nilai variabel independen yang berada di luar rentang data yang ada.
Model Regresi Linier
Berikut adalah contoh kasus sederhana yang akan kita gunakan pada pembahasan materi ini. Contoh ini akan berfokus pada hubungan antara usia dan tekanan darah sistolik.Kita tertarik untuk mengetahui apakah ada hubungan antara usia dan tekanan sistolik, dan jika ada, seberapa kuat hubungan tersebut.
Contoh Kasus:
Individu | Usia (tahun) X | Tekanan Darah Sistolik (mm Hg) Y |
A | 34 | 108 |
B | 43 | 129 |
C | 49 | 126 |
D | 58 | 149 |
E | 64 | 168 |
F | 73 | 161 |
G | 78 | 174 |
Dengan data ini, kita dapat menerapkan berbagai konsep dan metode analisis regresi:
Pemahaman Dasar: Kita dapat menjelaskan bahwa tujuan Kita adalah untuk menentukan apakah usia dapat digunakan untuk memprediksi tekanan sitolik, dan bahwa Kita akan menggunakan regresi linier untuk melakukan ini.
Model Regresi Linier: Kita dapat menunjukkan bagaimana model regresi linier dirumuskan, dengan usia sebagai variabel bebas X dan tekanan darah sistolik sebagai variabel terikat Y.
Estimasi Parameter: Kita dapat menjelaskan bagaimana koefisien regresi dihitung menggunakan metode kuadrat terkecil, dan kemudian menghitung koefisien tersebut menggunakan data Kita.
Metode Pencocokan Garis Regresi (Fitting the Regression Line)
Dalam analisis regresi linier, salah satu aspek yang sangat penting adalah pencocokan garis regresi ke dalam kumpulan data yang telah diamati. Tujuannya adalah untuk mendapatkan garis yang paling mewakili pola hubungan antara variabel independen (X) dan variabel dependen (Y). Proses ini seringkali dikenal dengan istilah 'fitting the regression line' atau pencocokan garis regresi.
Dalam regresi linier sederhana, garis regresi didefinisikan oleh persamaan matematis:
$$\hat{Y}=b_0+\ b_1X$$
Nilai b0 dan b1 ini yang perlu kita temukan sehingga garis regresi tersebut paling cocok dengan data yang kita miliki.
Dalam contoh kasus di atas, persamaan $\hat{Y}=b_0+\ b_1X$ dapat diinterpretasikan sebagai berikut:
- $b_0$ adalah rata-rata tekanan darah sistolik ketika usia adalah 0. Namun, interpretasi ini mungkin tidak masuk akal dalam konteks ini karena tidak mungkin seseorang memiliki usia 0.
- $b_1$ adalah perubahan dalam pengeluaran untuk setiap perubahan satu unit dalam pendapatan. Misalnya, jikab1 adalah 0.5, maka untuk setiap peningkatan usia sebesar satu unit, kita dapat mengharapkan tekanan darah sistolik untuk meningkat sebesar 0.5 unit.
Dengan model regresi ini, kita dapat memprediksi tekanan darah sistolik berdasarkan usia. Namun, perlu diingat bahwa model regresi hanya menggambarkan hubungan rata-rata antara variabel. Ada juga variasi acak yang tidak dapat dijelaskan oleh model.
Estimasi parameter pada model regresi
Setiap model regresi mengandung dua komponen utama, yaitu hubungan prediktif antara variabel independen dan dependen, serta komponen acak atau galat (error) yang tidak dapat dijelaskan oleh model. Oleh karena itu, model regresi bisa ditulis dalam bentuk:
$$Data = Model + error$$
$$y = {b_0} + {b_1}x + \varepsilon $$
Data adalah variabel dependen (Y) yang ingin kita prediksi, Model adalah persamaan garis regresi (b0 + b1X), dan Error adalah penyimpangan nilai data observasi dari nilai yang diestimasikan oleh garis regresi.
Model regresilinier sederhana mencakup dua koefisien utama, yaitu: slope dan intersep.
- Slope: Dalam matematika, slope menggambarkan kemiringan suatu garis. Dalam statistika, slope menunjukkan besarnya kontribusi variabel X terhadap variabel Y. Nilai slope bisa diartikan sebagai rata-rata penambahan (atau pengurangan) yang terjadi pada variabel Y untuk setiap peningkatan satu satuan pada variabel X. Terdapat hubungan matematik yang erat antara slope dalam regresi linier dengan koefisien korelasi.
- Intersep: Intersep adalah titik perpotongan antara garis regresi dan sumbu Y saat nilai X adalah 0. Secara statistik, ini berarti nilai rata-rata pada variabel Y saat variabel X bernilai 0. Dengan kata lain, jika X tidak memberikan kontribusi, maka secara rata-rata, variabel Y akan bernilai sebesar intersep. Meski intersep adalah suatu konstanta dalam model regresi, makna praktisnya bisa kurang penting, terutama jika nilai X dalam data tidak ada yang bernilai 0 atau mendekati 0. Dalam hal ini, intersep mungkin tidak perlu ditafsirkan.
Nilai prediksi dan residual
Analisis regresi merupakan teknik yang digunakan untuk membangun persamaan dan menggunakan persamaan tersebut untuk membuat perkiraan atau prediksi. Karena merupakan prediksi, nilai yang diprediksi tidak selalu sesuai dengan nilai aktualnya. Semakin kecil perbedaan antara nilai prediksi dengan nilai aktualnya, semakin tepat persamaan regresinya. Perbedaan antara nilai prediksi (y) dengan nilai aktualnya disebut sebagai residual atau error.
Persamaan regresi bisa ditulis sebagai:
$$Data = Model + error$$
$${y_i} = {b_0} + {b_1}{x_i} + {\varepsilon _i}$$
$${y_i} = ({b_0} + {b_1}{x_i}) + {\varepsilon _i}$$
$${y_i} = {\hat y_i} + {\varepsilon _i}$$
$${\varepsilon _i} = {y_i} - {\hat y_i}$$
Di mana ${\varepsilon _i}$ adalah nilai residual, dengan ${\hat y_i}$ adalah nilai prediksi dan ${Y_i}$ adalah nilai aktual.
Misalkan untuk contoh kasus di atas, persamaan regresinya sebagai berikut: y = 61.244 + 1.4694x. Dengan menggunakan persamaan tersebut kita bisa menghitung nilai prediksi dan residualnya seperti pada tabel di bawah ini.
Individu | X | Y | Prediksi ($\hat Y$) | Residual (e) |
A | 34 | 108 | 111.20 | -3.20 |
B | 43 | 129 | 124.43 | 4.57 |
C | 49 | 126 | 133.24 | -7.24 |
D | 58 | 149 | 146.47 | 2.53 |
E | 64 | 168 | 155.29 | 12.71 |
F | 73 | 161 | 168.51 | -7.51 |
G | 78 | 174 | 175.86 | -1.86 |
Jumlah | 0.00 |
Nilai residual ini digunakan untuk menentukan garis regresi terbaik yang paling mencerminkan data observasi dan merupakan persamaan regresi yang terbaik dari berbagai kemungkinan garis lurus lain yang mungkin dibuat.
Jumlah nilai error (residual) adalah nol.
$$\sum {y_i} - {\hat y_i} = 0$$
Garis regresi terbaik (best fitting)adalah jika jumlah kuadrat perbedaan antara nilai prediksi dan nilai aktual variabel dependen data sampel adalah yang terkecil atau jumlah kuadrat residual tersebut minimum.
$$\sum {({y_i} - {\hat y_i})^2} = \sum {e^2} = minimum$$
Pendugaan model garis regresi dengan cara tersebut dinamakan dengan ordinary least squares (OLS) atau metode kuadrat terkecil, yaitu suatu metode pendugaan parameter dengan meminimumkan jumlah kuadrat error (Sum Square of Error = SSE).
$$SSE = \sum {e_i}^2 = minimum$$
Untuk menyelesaikan persamaan ini, kita bisa menggunakan prosedur berikut:
Kita akan meminimumkan nilai SSE:
$$SSE = \sum {e_i}^2 = \sum {({y_i} - {\hat y_i})^2} = \sum {({y_i} - {b_0} - {b_1}{x_i})^2}$$
Selanjutnya persamaan tersebut kita turunkan untuk mendapatkan nilai dugaan b0 dan b1:
$$\frac{{\partial SSE}}{{\partial {b_0}}} = 0\;{\rm{dan}}\frac{{\partial SSE}}{{\partial {b_1}}} = 0$$
Sehingga akan diperoleh persamaan berikut:
$${b_1} = \frac{{S{S_{xy}}}}{{S{S_{xx}}}}{\rm{ dan }}{b_0} = \bar y - {b_1}\bar x$$
Dimana:
$S{S_{xx}} = \;\mathop \sum \limits_{i = 1}^n {\left( {{X_i} - \bar X} \right)^2}$
$S{S_{xy}} = \;\mathop \sum \limits_{i = 1}^n \left( {{X_i} - \bar X} \right)\left( {{Y_i} - \bar Y} \right)$
Dengan demikian, kita sekarang sudah mendapatkan persamaan untuk menduga nilai b0 dan b1.
$${b_1} = \;\frac{{\mathop \sum \nolimits_{i = 1}^n \left( {{x_i} - \bar x} \right)\left( {{y_i} - \bar y} \right)}}{{\mathop \sum \nolimits_{i = 1}^n {{\left( {{x_i} - \bar x} \right)}^2}}}$$
dan
$${b_0} = \bar y - {b_1}\bar x$$
Untuk memudahkan dalam perhitungan, bentuk lain persamaan untuk koefisien b1:
$${b_1} = \;\frac{{n\sum {x_i}{y_i} - \sum {x_i}\sum {y_i}}}{{n\sum x_i^2 - {{\left( {\sum {x_i}} \right)}^2}}}$$
Atau
$${b_1} = \;\frac{{\sum {x_i}{y_i} - \frac{{\sum {X_i}\sum {Y_i}}}{n}}}{{\sum x_i^2 - \frac{{{{\left( {\sum {x_i}} \right)}^2}}}{n}}}$$
Contoh terapan:
Kita akan menggunakan rumus tersebut untuk menghitung koefisien regresi. Berikut adalah langkah-langkah penghitungannya:
Langkah 1: Buat Tabel berikut
Individu | X | Y | X2 | Y2 | XY |
A | 34 | 108 | 1156 | 11664 | 3672 |
B | 43 | 129 | 1849 | 16641 | 5547 |
C | 49 | 126 | 2401 | 15876 | 6174 |
D | 58 | 149 | 3364 | 22201 | 8642 |
E | 64 | 168 | 4096 | 28224 | 10752 |
F | 73 | 161 | 5329 | 25921 | 11753 |
G | 78 | 174 | 6084 | 30276 | 13572 |
Jumlah (Σ) | 399 | 1015 | 24279 | 150803 | 60112 |
Rata-rata | 57 | 145 |
Dari tabel tersebut kita dapatkan:
- ΣX = 399 (total usia)
- ΣY=1015 (total tekanan darah sistolik)
- ΣXY=60112 (total produk dari X dan Y)
- ΣX2 =24279 (total kuadrat dari X)
Langkah 2: Menghitung nilai b1 dan b0
Setelah kita mendapatkan nilai-nilai ini, kita bisa memasukkannya ke dalam rumus tadi:
Menggunakan rumus untuk b1:
$${b_1} = \;\frac{{n\sum {x_i}{y_i} - \sum {x_i}\sum {y_i}}}{{n\sum x_i^2 - {{\left( {\sum {x_i}} \right)}^2}}}$$
kita dapatkan:
${b_1} = \;\frac{{7\left( {60112} \right) - \left( {399} \right)\left( {1015} \right)}}{{7\left( {24279} \right) - {{\left( {399} \right)}^2}}}$
${b_1} = \;1.4694\;\;\;$
Setelah menghitung, kita akan mendapatkan nilai b1, yaitu gradien garis regresi.
Kemudian, kita masukkan nilai b1 ini ke dalam rumus untuk mendapatkan b0:
${b_0} = \bar y - {b_1}\bar x$
kita dapatkan:
${b_0} = 145 - 1.4694\left( {399} \right)$
${b_0} = 61.2441$
Setelah menghitung, kita akan mendapatkan nilai b0, yaitu titik potong garis regresi dengan sumbu Y.
Langkah 3: Menulis Persamaan Regresi
Setelah mendapatkan b0 dan b1, kita dapat menulis persamaan regresi:
$y = 61.244 + 1.4694x$
Berikut interpretasi persamaan ini:
- b0= 61.244 adalah rata-rata tekanan darah sistolik ketika usia adalah 0 tahun. Dalam konteks ini, interpretasi ini mungkin tidak praktis, karena pendidikan umumnya tidak akan 0 tahun. Interpretasi ini lebih dari sebuah formalitas matematika daripada sesuatu yang bisa digunakan dalam praktik klinis.
- b1= 1.4694 adalah perubahan dalam tekanan darah sistolik untuk setiap peningkatan satu tahun dalam usia. Misalnya, untuk setiap peningkatan satu tahun dalam usia, kita dapat mengharapkan tekanan darah sistolik akan meningkat sebesar 1.4694 mm Hg.

Dalam praktiknya, persamaan ini dapat digunakan untuk memprediksi tekanan darah sistolik berdasarkan usia. Misalnya, jika seseorang memiliki usia 64 tahun, tekanan darah sistolik yang diharapkan akan menjadi:
$y = 61.244 + 1.4694x$
$y = 61.244 + 1.4694\left( {64} \right)$
$y = 155.2858$
Jadi, tekanan darah sistolik yang diharapkan untuk seseorang dengan usia 64 tahun adalah 155.29 mm Hg.
Model ini adalah perkiraan dan sebenarnya ada banyak faktor lain yang dapat mempengaruhi tekanan darah seseorang. Model regresi linier sederhana ini hanya mempertimbangkan satu variabel prediktor (usia), tetapi dalam praktiknya, analisis yang lebih kompleks mungkin diperlukan.
Untuk Residual (e):
Residual adalah perbedaan antara nilai sebenarnya (Y) dan nilai yang diprediksi ($\hat{Y}$). Residual ini akan memberikan kita gambaran sejauh mana model kita mampu memprediksi data yang sebenarnya.
Untuk individu kelima (E), residualnya adalah e = Y - $\hat{Y}$ = 168 - 155.29 = 12.71.
Kita juga dapat mengulangi proses ini untuk setiap individu dalam dataset Kita.
Residual bisa digunakan untuk memeriksa asumsi model dan memahami sejauh mana model dapat menjelaskan variasi dalam data. Misalnya, jika residual memiliki pola tertentu atau tidak berdistribusi secara normal, ini bisa menjadi tanda bahwa model tidak sesuai dengan data dengan baik.
Perlu diperhatikan bahwa perhitungan ini adalah dasar dari regresi linier sederhana dan pengujian lanjutan seperti analisis residu dan validasi model dapat digunakan untuk lebih memahami kinerja model dan asumsi yang mendasarinya.
Evaluasi Model Regresi
Jumlah Kuadrat yang Dijelaskan dan Tidak Dijelaskan (Explained and Unexplained Sum of Squares)
Dalam analisis regresi, kita seringkali tertarik untuk mengetahui sejauh mana variasi dalam variabel dependen dapat dijelaskan oleh variabel independen dalam model. Untuk tujuan ini, kita bisa membandingkan Jumlah Kuadrat yang Dijelaskan (SSR) dengan Jumlah Kuadrat yang Tidak Dijelaskan (SSE).
Sebagai contoh, perhatikan gambar di bawah ini. Kita asumsikan bahwa kita memiliki sekumpulan data berpasangan dan nilai prediksi y diperoleh dengan menggunakan persamaan regresi. Rata-rata dari sampel y adalah $\bar y$.

- Total deviasi (dari rata-rata) untuk titik tertentu (x, y) adalah jarak vertikal $y - \bar y$, yaitu jarak antara titik (x, y) dengan garis horizontal yang melewati nilai rata-rata sampel.
- Deviasi yang dapat dijelaskan (explained deviation) adalah jarak vertikal $\hat y - \bar y$, yaitu jarak antara nilai prediksi dengan garis yang melalui nilai rata-rata sampel
- Deviasi yang tidak dapat dijelaskan (unexplained deviation) adalah jarak vertikal $y - \hat y$, yaitu jarak antara titik (x, y) dengan garis regresi. Pada bahasa sebelumnya, jarak ini dikenal dengan residual/error/sisaan/galat.
Dengan demikian, kita dapat menulis:
$$Total\;Deviation = Explained\;Deviation + Unexplained\;Deviation$$
atau dalam bentuk matematis:
$$\left( {{y_i} - \bar y} \right) = \left( {{{\hat y}_i} - \bar y} \right) + \left( {{y_i} - {{\hat y}_i}} \right)$$
Ini adalah identitas dasar dalam regresi. Dengan mengkuadratkan kedua sisi persamaan dan menjumlahkannya untuk semua titik data, kita mendapatkan:
$$Total\;Variation = Explained\;Variation + Unexplained\;Variation$$
${\rm{\Sigma }}{\left( {{y_i} - \bar y} \right)^2} = {\rm{\Sigma }}{\left( {{{\hat y}_i} - \bar y} \right)^2} + {\rm{\Sigma }}{\left( {{y_i} - {{\hat y}_i}} \right)^2}$
atau dengan kata lain:
$$SST = SSR + SSE\;$$
di mana:
- SST = Jumlah Kuadrat Total (Sum of Squares Total)
- SSR = Jumlah Kuadrat yang Dijelaskan (Sum of Squares Regression)
- SSE = Jumlah Kuadrat yang Tidak Dijelaskan (Sum of Square Error)
Secara sederhana, Jumlah Kuadrat Total (SST) terdiri dari Jumlah Kuadrat yang Dijelaskan (SSR) dan Jumlah Kuadrat yang Tidak Dijelaskan (SSE). Dalam konteks ini, SSR merepresentasikan variasi dalam data yang bisa dijelaskan oleh model, sedangkan SSE merepresentasikan variasi yang tidak bisa dijelaskan oleh model.
Kita dapat menggambarkan konsep ini dengan contoh berikut:
Contoh Terapan
Misalkan kita memiliki data berikut dan kita telah memperoleh nilai prediksi ${\rm{\hat Y}}$ untuk setiap titik data menggunakan model regresi kita.
Individu | X | Y | ${\rm{\hat Y}}$ | Kuadrat Total${\left( {{y_i} - \bar y} \right)^2}$ | Kuadrat Regresi ${\left( {{{\hat y}_i} - \bar y} \right)^2}$ | Kuadrat Eror${\left( {{y_i} - {{\hat y}_i}} \right)^2}$ |
A | 34 | 108 | 111.20 | 1369.00 | 1142.18 | 10.26 |
B | 43 | 129 | 124.43 | 256.00 | ${\rm{\hat Y}}$.19 | 20.90 |
C | 49 | 126 | 133.24 | 361.00 | 138.18 | 52.49 |
D | 58 | 149 | 146.47 | 16.00 | 2.16 | 6.40 |
E | 64 | 168 | 155.29 | 529.00 | 105.80 | 161.65 |
F | 73 | 161 | 168.51 | 256.00 | 552.74 | 56.41 |
G | 78 | 174 | 175.86 | 841.00 | 952.18 | 3.45 |
Rata-rata | 57 | 145 | ||||
${\rm{\Sigma }}$ | 3628.00 | 3316.44 | 311.56 |
Dari tabel tersebut kita bisa dapatkan nilai-nilai berikut:
- Jumlah Kuadrat Total (SST) = 3628.00
- Jumlah Kuadrat Regresi (SSR) = 3316.44
- Jumlah Kuadrat Error (SSE) = 311.56
Dari contoh ini, kita dapat melihat bahwa SST, SSR, dan SSE masing-masing mewakili komponen variasi total dalam data. Dengan membandingkan nilai-nilai ini, kita dapat menilai sejauh mana variasi dalam data dijelaskan oleh model regresi kita.
Koefisien Determinasi
Koefisien determinasi (R²) merupakan metrik yang digunakan untuk mengukur seberapa baik model regresi menjelaskan variasi dalam data. Nilai R² mencerminkan proporsi total variasi dalam variabel dependen Y yang dapat dijelaskan oleh variabel independen X yang ada dalam model persamaan regresi. Dengan kata lain, R² memberikan ukuran seberapa baik model kita mencocokkan data.
Koefisien determinasi (R2) dihitung dengan menggunakan persamaan berikut:
$${R^2} = \frac{{Expained\;Variation}}{{Total\;Variation}} = \frac{{SSR}}{{SST}}$$
Atau dalam bentuk matematis:
$${R^2} = \frac{{{\rm{\Sigma }}{{\left( {{{\hat y}_i} - \bar y} \right)}^2}}}{{{\rm{\Sigma }}{{\left( {{y_i} - \bar y} \right)}^2}}}$$
Dalam formula tersebut, SSR adalah jumlah variasi yang dijelaskan oleh model (Sum of Squares Regression), sementara SST adalah total variasi dalam data (Sum of Squares Total). Nilai $\hat y$ adalah nilai prediksi dari model kita, dan $\bar y$ adalah rata-rata nilai Y dalam sampel data.
Nilai R² berkisar antara 0 dan 1. Nilai yang mendekati 1 menunjukkan bahwa model kita dapat menjelaskan sebagian besar variasi dalam data, sedangkan nilai yang mendekati 0 menunjukkan bahwa model kita menjelaskan sedikit variasi dalam data.
Namun, penting untuk diingat bahwa R² bukanlah penilai tunggal dari kualitas model regresi kita. Nilai R² yang tinggi tidak selalu berarti bahwa kita memiliki model yang baik. Sebaliknya, nilai R² yang rendah tidak selalu berarti model kita buruk. R² hanya memberi kita informasi tentang sejauh mana variasi dalam data dijelaskan oleh model. Untuk menilai kualitas model regresi, kita juga harus mempertimbangkan metrik lain dan pengetahuan domain yang relevan.
Contoh Terapan
Misalkan kita sudah mendapatkan nilai SSR dan SST dari contoh sebelumnya. Dengan menggunakan rumus di atas, kita dapat menghitung R² sebagai berikut:
$${R^2} = \frac{{SSR}}{{SST}} = \frac{{3316.44}}{{3628.00}} = 0.9141$$
Ini berarti bahwa model regresi kita dapat menjelaskan sekitar 91.41% variasi dalam data. Namun, perlu diingat bahwa ini bukan satu-satunya metrik yang perlu dipertimbangkan saat mengevaluasi model regresi.
Kesalahan Standar Estimasi (Standard Error of Estimation)
Kesalahan Standar Estimasi (Standard Error of the Estimate, atau se) adalah metrik statistik yang digunakan untuk mengukur sejauh mana titik data individu berbeda dari garis regresi yang telah ditentukan oleh model. Secara lebih sederhana, se memberikan ukuran presisi model dalam memprediksi nilai variabel dependen berdasarkan nilai variabel independen. Nilai se yang lebih kecil mengindikasikan bahwa model lebih akurat dalam meramal nilai variabel dependen.
Secara matematis, se dihitung dengan menggunakan rumus:
$${s_e} = \sqrt {\frac{1}{{n - 2}}\mathop \sum \nolimits_1^n {{({y_i} - {{\hat y}_i})}^2}} $$
Keterangan:
- n adalah jumlah pengamatan dalam data.
- ${y_i}$ adalah nilai sebenarnya dari variabel dependen.
- $\hat y$ adalah nilai prediksi dari variabel dependen yang dihasilkan oleh model regresi.
- ${s_e}$ adalah kesalahan standar estimasi (standard error of estimation).
Namun, jika Kita melakukan perhitungan manual, Kita dapat menggunakan rumus berikut:
$${s_e} = \sqrt {\frac{{\sum y_i^2 - \frac{{{{\left( {\sum {y_i}} \right)}^2}}}{n} - {b_1}\left[ {\sum {x_i}{y_i} - \frac{{\sum {x_i}\sum {y_i}}}{n}} \right]}}{{n - 2}}} $$
Atau
$${s_e} = \sqrt {\frac{{\sum y_i^2 - {b_0}\sum {y_i} - {b_1}\sum {x_i}{y_i}}}{{n - 2}}} $$
Perlu diperhatikan bahwa rumus di atas mengasumsikan bahwa jumlah derajat kebebasan (df) untuk model ini adalah n−2, yang biasanya benar untuk regresi linier sederhana. Jumlah derajat kebebasan akan berbeda untuk jenis regresi yang lebih kompleks, misalnya regresi berganda.
Kesalahan Standar Estimasi dapat digunakan untuk membantu menilai kualitas suatu model regresi. Secara umum, semakin kecil nilai se, semakin baik model dalam memprediksi nilai variabel dependen berdasarkan nilai variabel independen.
Contoh Terapan
Dalam contoh ini, kita akan menghitung Kesalahan Standar Estimasi (Standard Error of Estimation, se) menggunakan dua metode: metode langsung dari definisi se dan metode manual dengan menggunakan formula tambahan.
Metode Langsung
Menggunakan formula dasar dari Kesalahan Standar Estimasi:
$${s_e} = \sqrt {\frac{1}{{n - 2}}\mathop \sum \nolimits_1^n {{({y_i} - {{\hat y}_i})}^2}} $$
Kita mengetahui bahwa n (jumlah pengamatan) adalah 7 dan total dari kuadrat error (SSE) adalah 311.56 (seperti yang telah dihitung pada sub bab sebelumnya). Maka,
$${s_e} = \sqrt {\frac{1}{{7 - 2}}\left( {311.56} \right)} = \sqrt {62.3124} = 7.8938$$
Ini berarti, rata-rata, titik data sebenarnya berada sekitar 7.89 unit dari garis regresi.
Metode Manual
Dengan menggunakan formula manual:
$${s_e} = \sqrt {\frac{{\sum y_i^2 - {b_0}\sum {y_i} - {b_1}\sum {x_i}{y_i}}}{{n - 2}}} $$
Sebelumnya, kita telah mengetahui bahwa $\sum y_i^2$ adalah 150803, b0 adalah 61.2441, $\sum {y_i}$ adalah 1015, b1 adalah 1.4694, dan$\sum {x_i}{y_i}$ adalah 60112.
Jadi, substitusikan nilai-nilai tersebut ke dalam formula:
$${s_e} = \sqrt {\frac{{150803\; - 61.2441\left( {1015} \right) - \;1.4694\left( {60112} \right)}}{{7 - 2}}} = \sqrt {62.3124} = 7.8938$$
Nilai ini sama dengan nilai yang dihitung menggunakan metode langsung, sehingga kita dapat memastikan bahwa perhitungan kita benar. Nilai ini juga menunjukkan bahwa model kita cukup akurat, dengan rata-rata kesalahan sebesar 7.89 unit.
Perlu diingat bahwa perhitungan ini berlaku untuk regresi linier sederhana, dan kesalahan standar estimasi dapat berbeda untuk jenis regresi yang lebih kompleks.
Analisis Varians (ANOVA) dalam Model Regresi
Analisis Varians, atau yang lebih dikenal dengan ANOVA, adalah teknik statistik yang digunakan untuk menguji sejauh mana variabel independen dalam model regresi mempengaruhi variabel dependen. Dalam konteks model regresi, ANOVA digunakan untuk menguji hipotesis bahwa model regresi yang telah kita fiturkan secara signifikan menjelaskan variasi dalam data.
Secara spesifik, kita menggunakan ANOVA untuk menguji hipotesis null bahwa semua koefisien regresi (kecuali intersep) adalah nol, berbanding dengan hipotesis alternatif bahwa setidaknya satu koefisien regresi tidak nol. Jika kita menolak hipotesis null, ini menunjukkan bahwa model regresi kita secara signifikan menjelaskan variasi dalam data.
ANOVA dalam model regresi biasanya melibatkan konsep-konsep berikut:
- Jumlah Kuadrat Total (SST): Ini adalah variasi total dalam data. SST dihitung sebagai jumlah kuadrat selisih antara setiap observasi dan rata-rata observasi.
- Jumlah Kuadrat Regresi (SSR): Ini adalah variasi yang dijelaskan oleh model regresi. SSR dihitung sebagai jumlah kuadrat selisih antara nilai prediksi model dan rata-rata observasi.
- Jumlah Kuadrat Error (SSE): Ini adalah variasi yang tidak dijelaskan oleh model. SSE dihitung sebagai jumlah kuadrat selisih antara setiap observasi dan nilai prediksi model.
Tabel ANOVA akan terlihat seperti ini:
Sumber Variasi | Jumlah Kuadrat | Derajat Kebebasan | Rata-rata Kuadrat | Statistik F | Nilai P |
Regresi | SSR | k | MSR = SSR/k | F = MSR/MSE | P-value |
Error | SSE | n-k-1 | MSE = SSE/(n-k-1) | ||
Total | SST | n-1 |
Keterangan:
- n adalah jumlah pengamatan.
- k adalah jumlah variabel independen.
F-statistik digunakan untuk menguji hipotesis nol bahwa semua koefisien regresi adalah nol, yang berarti variabel independen tidak memiliki efek terhadap variabel dependen. Jika nilai P kurang dari tingkat signifikansi yang ditentukan (misalnya 0,05), maka kita menolak hipotesis nol dan menyimpulkan bahwa setidaknya satu dari variabel independen tersebut signifikan dalam memprediksi variabel dependen.
Dalam praktiknya, hasil ANOVA memberikan gambaran umum tentang kecocokan model. Namun, lebih dari sekadar melihat nilai P, penting juga untuk menilai asumsi-asumsi model, relevansi variabel dalam model, dan potensi multicollinearity atau ketergantungan antara variabel independen.
Contoh Terapan
Dalam contoh ini, kita akan menerapkan konsep Analisis Varians (ANOVA) dalam konteks regresi linier sederhana. Tujuannya adalah untuk memahami sejauh mana model regresi yang telah kita bentuk dapat menjelaskan variasi dalam data. Kita akan menggunakan tabel ANOVA untuk menginterpretasikan hasil analisis ini.
Tabel ANOVA:
Sumber Ragam | Derajat Kebebasan (DB) | Jumlah Kuadrat (JK) | Kuadrat Tengah (KT) | F-Hitung | Nilai-P | F-0.05 | F-0.01 |
Regresi (Usia) | 1 | 3316.438 | 3316.438 | 53.223 ** | 0.001 | 6.608 | 16.258 |
Error | 5 | 311.5618 | 62.3124 | - | - | - | - |
Total | 6 | 3628 | - | - | - | - | - |
Berikut adalah interpretasi dari tabel ANOVA di atas:
- Regresi (Usia): Ini mengacu pada variasi dalam tekanan darah sistolik yang dapat dijelaskan oleh usia. Dengan jumlah kuadrat sebesar 3316.4382, ini menunjukkan bahwa usia menjelaskan sebagian besar variasi dalam tekanan darah sistolik.
- Error: Ini adalah variasi dalam tekanan darah sistolik yang tidak dijelaskan oleh usia. Dengan jumlah kuadrat sebesar 311.5618, ini menunjukkan bahwa masih ada variasi dalam tekanan darah sistolik yang tidak dijelaskan oleh model kita.
- Total: Ini adalah variasi total dalam tekanan darah sistolik. Nilai ini adalah jumlah dari jumlah kuadrat regresi dan jumlah kuadrat error.
- F-Hitung: Nilai F-Hitung sebesar 53.223 menunjukkan bahwa model regresi kita secara signifikan menjelaskan variasi dalam data, karena F-Hitung lebih besar dari nilai kritis pada tingkat signifikansi 0.05 dan 0.01.
- Nilai-P: Nilai p kurang dari 0.05, yang menunjukkan bahwa kita dapat menolak hipotesis null bahwa usia tidak memiliki efek signifikan pada tekanan darah sistolik. Dengan kata lain, usia memiliki efek signifikan pada tekanan darah sistolik.
Dengan demikian, berdasarkan analisis varians, kita dapat mengatakan bahwa model regresi yang kita bentuk secara signifikan menjelaskan variasi dalam tekanan darah sistolik, dan bahwa usia adalah prediktor yang signifikan dari tekanan darah sistolik.
Uji Model Regresi
Pengujian Model Regresi melibatkan dua jenis uji: uji simultan dan uji parsial.
Uji Simultan Model Regresi
Uji simultan dalam regresi linier bertujuan untuk menguji apakah model regresi yang telah dibuat secara umum diterima. Tujuan spesifik pengujian ini adalah untuk memastikan apakah ada hubungan linier antara variabel bebas X dan variabel terikat Y, atau setidaknya antara salah satu variabel bebas X dengan variabel terikat Y.
Pengujian ini dilakukan dengan pendekatan analisis ragam, dengan membagi total variasi dari variabel terikat menjadi dua komponen, yaitu:
SST = SSR + SSE
Hipotesis yang berlaku untuk pengujian ini adalah:
- H0: Semua koefisien regresi adalah nol (β1 = β2 = ... = βk = 0)
- H1: Setidaknya satu koefisien regresi tidak nol (ada setidaknya satu βi ≠ 0)
Pengujian ini menggunakan Uji F, dimana nilai F dihitung sebagai rasio varians yang dijelaskan oleh model (MSR) dengan varians yang tidak dijelaskan oleh model (MSE):
F = MSR / MSE
Contoh terapan:
Mengacu pada tabel ANOVA sebelumnya, nilai F-hitung (F-observed) adalah 53.223. Nilai ini mengindikasikan sejauh mana variasi dalam data dijelaskan oleh model dibandingkan dengan variasi yang tidak dijelaskan. Nilai p (0.001) kurang dari 0.05, yang berarti kita dapat menolak hipotesis null dan menyimpulkan bahwa setidaknya satu variabel bebas memiliki hubungan linier dengan variabel terikat.
Namun, penting untuk dicatat bahwa ini tidak berarti semua variabel bebas memiliki hubungan signifikan dengan variabel terikat. Untuk itu, kita perlu melakukan uji parsial atau uji t untuk setiap variabel bebas. Pengujian tersebut akan dibahas pada bagian selanjutnya.
Uji Parsial Model Regresi
Uji parsial digunakan untuk menguji secara individual apakah parameter b memiliki arti penting dalam model. Dalam kata lain, apakah sebuah variabel bebas X berkontribusi secara signifikan terhadap variabel terikat Y ketika diuji secara terpisah. Uji parsial dilakukan menggunakan uji t.
Langkah-langkah pengujian meliputi:
1. Menentukan Hipotesis:
Hipotesis nol (H0) dan hipotesis alternatif (H1) biasanya ditentukan sebagai berikut:
- H0: β = 0 (tidak ada pengaruh signifikan dari variabel independen terhadap variabel dependen)
- H1: β ≠ 0 (ada pengaruh signifikan dari variabel independen terhadap variabel dependen)
2. Melakukan Uji Statistik:
Uji statistik yang digunakan adalah uji t, yang dihitung sebagai berikut:
$$t = \frac{{b - \beta }}{{S{E_b}}}$$
di mana $S{E_b}$adalah kesalahan standar dari koefisien regresi, dan b adalah estimasi dari koefisien regresi tersebut.
Uji untuk b1 (koefisien regresi):
$$t = \frac{{{b_1} - {\beta _1}}}{{S{E_{b1}}}}$$
di mana $S{E_{{b_1}}}$ adalah standar error koefisien regresi dan dapat dihitung menggunakan rumus:
$$S{E_{{b_1}}} = \sqrt {\frac{{s_e^2}}{{\sum {{\left( {{x_i} - \bar x} \right)}^2}}}} \;\; = \;\sqrt {\frac{{s_e^2}}{{\sum x_i^2 - \frac{{{{\left( {\sum {x_i}} \right)}^2}}}{n}}}} $$
Kesalahan Standar Estimasi (Standard Error of the Estimate, atau se) merupakan ukuran yang menggambarkan seberapa baik model regresi kita mencocokkan data yang kita miliki. Nilai ini dihitung dengan menggunakan rumus yang sudah dijelaskan pada bab sebelumnya. Pada dasarnya, se merupakan akar kuadrat dari rata-rata kuadrat kesalahan atau residu, yaitu perbedaan antara nilai yang diobservasi dan nilai yang diprediksi oleh model.
Uji untuk b0 (intersep):
$$t = \frac{{{b_0} - {\beta _0}}}{{S{E_{b0}}}}$$
$S{E_{b0}}$adalah standar error intersep dan dapat dihitung dengan rumus:
$${\rm SE}_{b_0}=\sqrt{s_e^2}\ \bullet\sqrt{\frac{\sum x_i^2}{n\sum{(x_i-\bar{x})}^2}}$$
atau
$${\rm SE}_{b_0}=s_e\ \bullet\sqrt{\frac{1}{n}+\frac{{\bar{x}}^2}{\sum{(x_i-\bar{x})}^2}}$$
atau
$${\rm SE}_{b_0}=s_e\ \bullet\sqrt{\frac{1}{n}+\frac{\left(\frac{\sum x_i}{n}\right)^2}{\sum{x_i^2-\frac{\left({\sum x}_i\right)^2}{n}}}}$$
Pengambilan keputusan:
Uji hipotesis dilakukan dengan menghitung statistik t dan membandingkannya dengan nilai kritis dari distribusi tpada taraf signifikansi α dengan derajat kebebasan (n-2). Jika nilai absolut dari statistik t lebih besar dari nilai kritis, kita dapat menolak hipotesis nol dan menyimpulkan bahwa variabel independen memiliki efek yang signifikan terhadap variabel dependen.
atau:
H0 ditolak jika |thitung|> tα/2; (n-2) pada taraf nyata α.
Contoh terapan
Uji untuk b1 (koefisien regresi):
Dari perhitungan sebelumnya kita sudah mendapatkan nilai se = 7.8951, $\sum x_i^2$ = 24279, $\sum {x_i}$= 399, n = 7. Selanjutnya kita masukkan ke dalam rumus:
$$S{E_{{b_1}}} = \sqrt {\frac{{{{\left( {7.8951} \right)}^2}}}{{24279 - \frac{{{{\left( {399} \right)}^2}}}{7}}}} = 0.2014$$
Sehingga:
$$t = \frac{{1.4694 - 0}}{{0.2014}} = 7.2954$$
Interpretasi:
Dengan nilai t hitung sebesar 7.2954 dan nilai t tabel pada α/2 (0.025) dengan derajat kebebasan 5 sebesar 2.571, kita dapat melihat bahwa nilai t hitung lebih besar dari t tabel. Oleh karena itu, H0 ditolak. Ini berarti variabel X1 memberikan kontribusi yang signifikan terhadap variabel Y.
Uji untuk b0 (intersep):
$${\rm SE}_{b_0}=s_e\ \bullet\sqrt{\frac{1}{n}+\frac{\left(\frac{\sum x_i}{n}\right)^2}{\sum{x_i^2-\frac{\left({\sum x}_i\right)^2}{n}}}}$$
$${\rm SE}_{b_0}=7.8938\ \bullet\sqrt{\frac{1}{7}+\frac{\left(\frac{399}{7}\right)^2}{24279-\frac{\left(399\right)^2}{7}}}=11.862$$
Sehingga:
$$t = \frac{{61.2441}}{{11.862 = }} = 5.16305$$
Interpretasi:
Dengan nilai t hitung sebesar 5.16305 dan nilai t tabel pada α/2 (0.025) dengan derajat kebebasan 5 sebesar 2.571, kita dapat melihat bahwa nilai t hitung lebih besar dari t tabel. Oleh karena itu, H0 ditolak. Hal ini menunjukkan bahwa intersep ($b_0$) signifikan dalam model regresi kita.
Asumsi dalam Analisis Regresi
Dalam melakukan analisis regresi linier, ada sejumlah asumsi klasik yang perlu dipenuhi. Asumsi-asumsi ini diuji menggunakan data residual, bukan data pengamatan, kecuali dalam kasus uji multikolinieritas. Berikut ini adalah asumsi-asumsi dalam analisis regresi:
1. Model Telah Dispesifikasikan dengan Benar
Asumsi ini merujuk pada kebutuhan bahwa model regresi harus dirancang dengan benar. Dalam konteks ini, "telah dispesifikasikan dengan benar" berarti bahwa model yang dibuat oleh peneliti sesuai dengan konsep teoritis kasus yang sedang diteliti. Untuk asumsi ini, tidak ada pengujian statistik tertentu yang dapat dilakukan karena asumsi ini sangat terkait dengan pemahaman teoritis peneliti tentang kasus yang diteliti.
Pada contoh kasus ini, konteks pengujian berfokus pada hubungan antara usia (variabel bebas) dan tekanan darah sistolik (variabel terikat), yang secara teoritis masuk akal karena peningkatan usia sering kali dihubungkan dengan peningkatan tekanan darah.
2. Kesalahan (Error) Menyebar Normal
Asumsi ini mensyaratkan bahwa error dari model regresi memiliki distribusi yang normal dengan rata-rata nol dan varians yang tetap. Ini dapat diuji menggunakan berbagai metode, seperti plot normal probabilitas, uji Shapiro-Wilk, atau uji Kolmogorov-Smirnov.
Berikut hasil beberapa uji normalitas:
Uji | Statistik | Nilai-P |
Shapiro-Wilk's | 0.927 | 0.523 |
Anderson Darling | 0.302 | 0.578 |
D'Agostino Pearson | 0.809 | 0.667 |
Liliefors | 0.173 | p > 0.20 |
Kolmogorov-Smirnov | 0.173 | p > 0.20 |
Berdasarkan hasil uji kenormalan yang Kita berikan (Shapiro-Wilk's, Anderson Darling, D'Agostino Pearson, Liliefors, dan Kolmogorov-Smirnov), semua p-value lebih besar dari 0.05. Ini berarti kita gagal menolak hipotesis nol bahwa residual berdistribusi normal. Jadi, asumsi ini terpenuhi.
3. Kesalahan (Error) Homoskedastis
Asumsi ini mensyaratkan bahwa varians dari error adalah konstan atau tidak berubah-ubah sepanjang garis regresi. Ketidaksesuaian dengan asumsi ini disebut heteroskedastisitas dan dapat diuji dengan plot residual atau menggunakan uji White atau uji Breusch-Pagan.
Berikut hasil uji homoskedastisitas:
DB | χ²-Hitung | Nilai-P | χ²-0.05 |
1 | 0.329 | 0.566 | 3.841 |
Uji Breusch–Pagan–Godfrey menghasilkan nilai p 0.566, yang lebih besar dari 0.05. Ini berarti kita gagal menolak hipotesis nol bahwa varians sama di semua grup (homoskedastisitas). Jadi, tidak ada bukti kuat tentang adanya heteroskedastisitas dalam model Kita, yang berarti asumsi ini juga terpenuhi.
4. Tidak Terdapat Autokorelasi dalam Kesalahan (Error)
Asumsi ini mengharuskan tidak ada korelasi antara error satu periode dengan error periode lainnya. Ketidaksesuaian dengan asumsi ini disebut autokorelasi dan dapat diuji dengan plot residual atau uji Durbin-Watson.
5. Tidak Terjadi Multikolinieritas
Asumsi ini berlaku dalam konteks regresi linier berganda, yang mensyaratkan tidak adanya korelasi sempurna antara dua atau lebih variabel bebas. Multikolinieritas merupakan istilah yang digunakan untuk menggambarkan ketidaksesuaian dengan asumsi ini dan dapat diuji dengan menggunakan Variance Inflation Factor (VIF) atau toleransi.
Berikut adalah petunjuk untuk interpretasi nilai Variance Inflation Factor (VIF):
- 1: tidak ada korelasi.
- 1 - 5: ada korelasi moderat.
- 5: korelasi yang kuat.
- 10: menunjukkan multikolinearitas
Pada model regresi yang kita miliki saat ini, hanya ada satu variabel bebas, yaitu usia. Karena itu, multikolinieritas (yang hanya dapat terjadi ketika ada dua atau lebih variabel bebas yang saling berkorelasi) tidak dapat terjadi. Oleh karenanya, asumsi ini juga telah terpenuhi.
Dengan memenuhi asumsi-asumsi ini, model regresi linier akan memiliki keandalan dan validitas yang lebih baik dalam menganalisis dan memprediksi data.
Berdasarkan hasil analisis dan pengujian asumsi regresi di atas, tampaknya model regresi linier untuk data ini memenuhi semua asumsi dan oleh karena itu, hasilnya bisa diandalkan dan valid.
Evaluasi Kualitas Model
Berikut adalah beberapa metrik yang sering digunakan dalam evaluasi kualitas model:
- Koefisien Determinasi (R2): Ini adalah metrik yang umum digunakan untuk mengevaluasi kualitas model regresi linier. R2 adalah proporsi dari varians total dari variabel dependen yang dijelaskan oleh model. Nilai R2 berkisar antara 0 dan 1, dengan 1 menunjukkan bahwa model menjelaskan seluruh varians dalam data, dan 0 menunjukkan bahwa model tidak menjelaskan varians apa pun.
- Adjusted R2: Meskipun R2 bisa menjadi metrik yang berguna, ia memiliki kekurangan yaitu nilainya cenderung meningkat saat kita menambahkan lebih banyak variabel ke model, terlepas dari apakah variabel tersebut benar-benar berguna untuk model. Oleh karena itu, Adjusted R2 seringkali lebih berguna, karena ia memperhitungkan jumlah variabel dalam model dan bisa menghukum model yang terlalu kompleks.
- Root Mean Squared Error (RMSE) dan Mean Absolute Error (MAE): Kedua metrik ini mengukur seberapa besar rata-rata kesalahan prediksi model. RMSE memberikan bobot yang lebih besar pada kesalahan besar (karena kesalahan dikuadratkan sebelum diambil rata-ratanya), sementara MAE memberikan bobot yang sama pada semua kesalahan.
- Residual Plots: Plot residual dapat memberikan wawasan visual yang berguna tentang bagaimana model berperilaku terhadap data. Idealnya, plot residual harus tampak acak (menunjukkan bahwa model menghasilkan kesalahan yang sama di semua tingkat variabel dependen), dan tidak ada pola yang jelas yang bisa diidentifikasi dalam plot.
- Uji Statistik: Banyak uji statistik digunakan dalam konteks regresi, termasuk uji t dan F untuk koefisien regresi, uji Durbin-Watson untuk autokorelasi, dan uji Breusch-Pagan untuk heteroskedastisitas.
- Cross-Validation: Cross-validation adalah teknik yang berguna untuk mengevaluasi seberapa baik model bisa memprediksi data baru. Dalam cross-validation, data dibagi menjadi beberapa subset, dan model ditrain menggunakan beberapa subset dan diuji pada subset yang tersisa.
- Akaike Information Criterion (AIC) dan Bayesian Information Criterion (BIC): Kedua metrik ini digunakan untuk membandingkan model yang berbeda dan menghukum model yang terlalu kompleks. Model dengan AIC atau BIC lebih rendah biasanya dianggap lebih baik.
Ingatlah bahwa tidak ada metrik tunggal yang bisa memberikan gambaran lengkap tentang kualitas model. Sebaliknya, harus dilakukan analisis komprehensif menggunakan berbagai metrik dan plot untuk mengevaluasi model regresi linier dengan baik. Selain itu, penilaian ini harus disesuaikan dengan konteks dan tujuan analisis. Misalnya, jika tujuan adalah prediksi, maka kita mungkin lebih peduli tentang seberapa baik model memprediksi data baru, sementara jika tujuan adalah pemahaman, kita mungkin lebih peduli tentang seberapa baik model menjelaskan data yang ada.
Interval Kepercayaan (Confidence Interval)
Interval kepercayaan adalah rentang nilai yang dihasilkan dari prosedur statistik yang digunakan untuk memperkirakan parameter populasi. Interval kepercayaan memberikan batas atas dan batas bawah untuk parameter yang diestimasi, yang mengandung nilai sebenarnya dari parameter tersebut dengan probabilitas tertentu. Tingkat probabilitas ini disebut tingkat kepercayaan dan biasanya ditetapkan pada 95% atau 99%.
Dalam konteks regresi linier, kita seringkali tertarik untuk menemukan interval kepercayaan untuk koefisien regresi, yang akan memberikan rentang estimasi di mana kita percaya koefisien populasi sebenarnya berada.
Interval kepercayaan untuk koefisien regresi β dapat dihitung dengan rumus berikut:
$$CI = b \pm t \times S{E_b}$$
di mana:
- CI adalah interval kepercayaan,
- b adalah estimasi koefisien regresi,
- t adalah nilai t pada tingkat signifikansi yang diinginkan (biasanya 0.05) untuk derajat kebebasan n - 2, dan
- SEb adalah kesalahan standar dari b.
Perhatikan bahwa $t \times S{e_b}$ adalah margin of error untuk estimasi kita.
Dengan interval kepercayaan, kita tidak hanya mendapatkan estimasi terbaik untuk parameter kita, tetapi juga pemahaman tentang sejauh mana estimasi ini mungkin berubah jika kita mengambil sampel berbeda dari populasi. Ini memberikan gambaran yang lebih lengkap tentang ketidakpastian seputar estimasi kita.
Interpolasi dan Ekstrapolasi
Interpolasi dan ekstrapolasi adalah dua teknik yang digunakan untuk memprediksi nilai variabel dependen dari nilai variabel independen dalam analisis regresi. Kedua teknik ini menggunakan model regresi yang telah diestimasi dari data yang ada.
Interpolasi adalah proses menggunakan model regresi untuk memprediksi nilai variabel dependen untuk nilai variabel independen yang berada di antara nilai-nilai minimum dan maksimum dalam data yang telah digunakan untuk mengestimasi model. Dalam kata lain, interpolasi digunakan untuk memprediksi nilai di "dalam" range data yang kita miliki.
Misalnya, jika kita memiliki model regresi dari data penjualan bulanan selama satu tahun, kita dapat menggunakan interpolasi untuk memprediksi penjualan di bulan ke-7 jika kita hanya memiliki data untuk bulan ke-6 dan bulan ke-8.
Ekstrapolasi, di sisi lain, adalah proses menggunakan model regresi untuk memprediksi nilai variabel dependen untuk nilai variabel independen yang berada di luar rentang nilai dalam data yang telah digunakan untuk mengestimasi model. Artinya, ekstrapolasi digunakan untuk memprediksi nilai di "luar" range data yang kita miliki.
Menggunakan contoh yang sama, kita dapat menggunakan ekstrapolasi untuk memprediksi penjualan di bulan ke-13 jika kita hanya memiliki data hingga bulan ke-12.
Perlu diperhatikan bahwa ekstrapolasi biasanya lebih berisiko dibandingkan dengan interpolasi, karena kita memprediksi nilai di luar range data yang kita miliki dan ini bisa mengakibatkan prediksi yang kurang akurat. Dalam melakukan ekstrapolasi, selalu penting untuk memastikan bahwa model yang kita gunakan masuk akal untuk nilai-nilai di luar range data kita.