Analisis Faktor adalah teknik statistik multivariat yang digunakan untuk mengidentifikasi variabel laten atau faktor yang mendasari sekumpulan variabel yang diamati. Tujuan utamanya adalah untuk mengurangi dimensi data dan mencari struktur dalam relasi antara variabel. Dengan kata lain, ini membantu kita memahami struktur variabel dan memindahkan informasi dari sejumlah besar variabel menjadi sejumlah lebih kecil dari faktor atau komponen.
Analisis Faktor memiliki peran yang penting dalam penelitian, terutama dalam penelitian yang melibatkan banyak variabel. Teknik ini membantu peneliti untuk mengurangi jumlah variabel dan menyederhanakan analisis. Selain itu, Analisis Faktor juga membantu dalam memahami struktur underlying dari data dan membangun model konseptual untuk penelitian lebih lanjut. Dalam konteks praktis, teknik ini sering digunakan dalam survei kepuasan pelanggan, penelitian psikologi, penelitian pemasaran, dan banyak bidang lainnya. Dalam semua kasus ini, Analisis Faktor membantu mengekstrak informasi yang berguna dan signifikan dari sejumlah besar data.
Terdapat dua jenis analisis faktor. Analisis Faktor Eksploratori (EFA): Jenis analisis faktor ini digunakan ketika kita tidak memiliki asumsi atau hipotesis tentang hubungan antara variabel. Tujuannya adalah untuk mengeksplorasi struktur atau model yang mungkin ada dalam data. Analisis Faktor Konfirmatori (CFA): Jenis analisis faktor ini digunakan ketika kita memiliki asumsi atau hipotesis tentang hubungan antara variabel dan kita ingin menguji atau mengkonfirmasi hipotesis tersebut.
Contoh Kasus
BFI (dataset based on personality assessment project)
Dataset ini terdiri dari 25 item penilaian karakteristik pribadi yang bersumber dari International Personality Item Pool (ipip.ori.org), yang merupakan bagian integral dari proyek Synthetic Aperture Personality Assessment (SAPA). Dataset ini melibatkan partisipasi dari 2800 individu dan bertujuan untuk menjadi alat demonstratif dalam pembuatan skala, analisis faktor, dan analisis berdasarkan Teori Respon Item. Dataset ini juga mencakup tiga variabel demografis tambahan: jenis kelamin, tingkat pendidikan, dan usia. Dalam studi kasus ini, hanya 2436 subjek yang data lengkapnya digunakan, sementara data yang tidak lengkap dihapus.
Item-item yang dievaluasi dalam penelitian ini dirancang berdasarkan lima faktor yang diajukan: Kesepakatan (Agreeableness), Kepedulian (Conscientiousness), Ekstraversi, Neurotisme, dan Keterbukaan (Opennness).
Data item tersebut dikumpulkan dengan menggunakan skala tanggapan 6 poin, dimulai dari 1 (Sangat Tidak Akurat), 2 (Cukup Tidak Akurat), 3 (Sedikit Tidak Akurat), 4 (Sedikit Akurat), 5 (Cukup Akurat), dan berakhir di 6 (Sangat Akurat). Pengumpulan data ini dilakukan sebagai bagian dari proyek Synthetic Aperture Personality Assessment (SAPA), yang dapat diakses di https://www.sapa-project.org/.
Sumber: https://vincentarelbundock.github.io/Rdatasets/datasets.html
Langkah-langkah Analisis Faktor:
- Aktifkan lembar kerja (Sheet) yang akan dianalisis.
- Tempatkan kursor pada Dataset (untuk membuat Dataset, lihat cara Persiapan Data).
- Apabila sel aktif (Active Cell) tidak berada pada Dataset, SmartstatXL otomatis akan mencoba menentukan Dataset secara otomatis.
- Aktifkan Tab SmartstatXL
- Klik Menu Multivariate > Analisis Faktor.

- SmartstatXL akan menampilkan kotak dialog untuk memastikan apakah Dataset sudah benar atau belum (biasanya alamat sel Dataset sudah otomatis dipilih dengan benar).

- Apabila sudah benar, Klik Tombol Selanjutnya
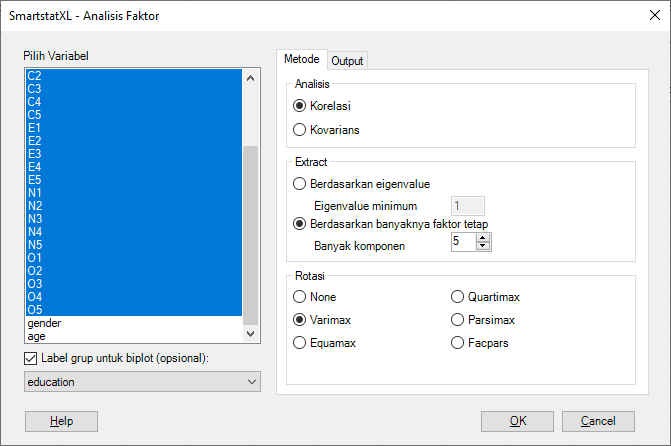
- Selanjutnya akan tampil Kotak Dialog Analisis Faktor:

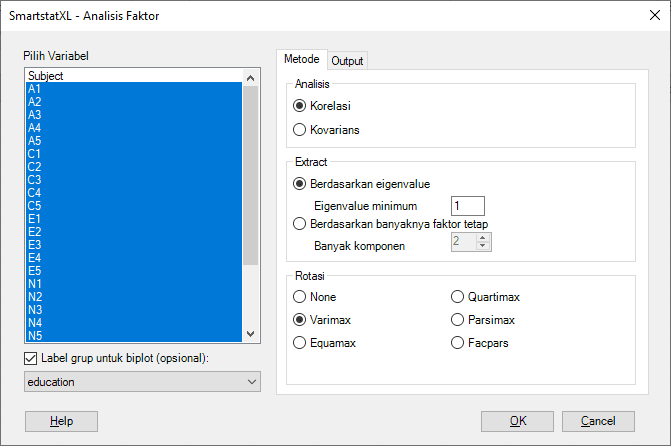
- Pilih Variabel, Metode Analisis dan Metode Ekstraksi serta label untuk untuk biplot (opsional). Pada contoh kasus ini kita tentukan:
- Variabel: A1, A2, ..., O4, O5
- Metode Analisis: Korelasi
- Metode Ekstrak: Berdasarkan Eigenvalue. Pada bagian akhir akan dicoba metode ekstraksi berdasarkan banyaknya faktor tetap (5 faktor)
- Rotasi: Varimax
- Label: Education (Opsional, digunakan untuk Biplot)
Selengkapnya bisa dilihat pada tampilan kotak dialog berikut:
Metode Analisis
Analisis berdasarkan kovarian biasanya digunakan ketika unit dari variabel yang diamati adalah sama atau ketika skala absolut variabel-variabel tersebut penting. Sebaliknya, analisis berdasarkan korelasi digunakan ketika unit dari variabel yang diamati berbeda atau ketika kita hanya tertarik pada hubungan antara variabel, bukan perbedaan absolutnya.
Metode Ekstrak
Dalam Analisis Komponen Utama (PCA), proses ekstraksi komponen umumnya melibatkan pencarian vektor eigen dan nilai eigen dari matriks kovariansi atau korelasi. Nilai eigen ini merepresentasikan sejauh mana varians dijelaskan oleh setiap komponen utama, dan vektor eigen menunjukkan kontribusi dari masing-masing variabel asli terhadap komponen utama tersebut.
Berikut adalah dua pendekatan umum dalam menentukan berapa banyak komponen atau faktor yang harus diekstrak:
- Berdasarkan Nilai Eigenvalue: Pendekatan ini, yang juga dikenal sebagai "kaidah eigenvalue satu" atau "Kaiser criterion", menyarankan bahwa kita hanya harus menyimpan komponen utama yang memiliki nilai eigen lebih besar dari 1. Ini didasarkan pada ide bahwa komponen utama harus menjelaskan varians lebih banyak daripada variabel asli rata-rata.
- Berdasarkan Banyaknya Komponen Tetap: Pendekatan ini melibatkan penentuan jumlah komponen atau faktor yang akan dipertahankan berdasarkan pengetahuan sebelumnya atau tujuan analisis. Misalnya, jika tujuan analisis adalah untuk mengurangi dimensi data menjadi dua atau tiga untuk tujuan visualisasi, maka kita mungkin memilih untuk mempertahankan hanya dua atau tiga komponen utama.
Kedua pendekatan ini memiliki kelebihan dan kekurangan. Pendekatan berdasarkan nilai eigen adalah aturan umum yang biasa digunakan, tetapi mungkin tidak selalu menghasilkan jumlah komponen yang paling sesuai untuk tujuan analisis. Pendekatan berdasarkan jumlah komponen tetap mungkin memerlukan pengetahuan lebih banyak tentang data dan tujuan analisis. Oleh karena itu, pilihan pendekatan terbaik mungkin akan bergantung pada konteks analisis.
Rotasi Varimax
Rotasi varimax adalah teknik rotasi ortogonal yang bertujuan untuk memaksimalkan varians dari kuadrat beban faktor di dalam setiap faktor, dengan kata lain, mencoba untuk memaksimalkan jumlah variabel yang memiliki skor loading tinggi pada suatu faktor dan skor loading rendah pada faktor lain.
- Tekan tab "Keluaran (Output)"
- Pilih output Analisis Faktor seperti pada tampilan berikut dengan menekan tombol Pilih Semua:
- Tekan tombol OK untuk membuat outputnya dalam Lembar Output



Hasil Analisis
Informasi Analisis Faktor.
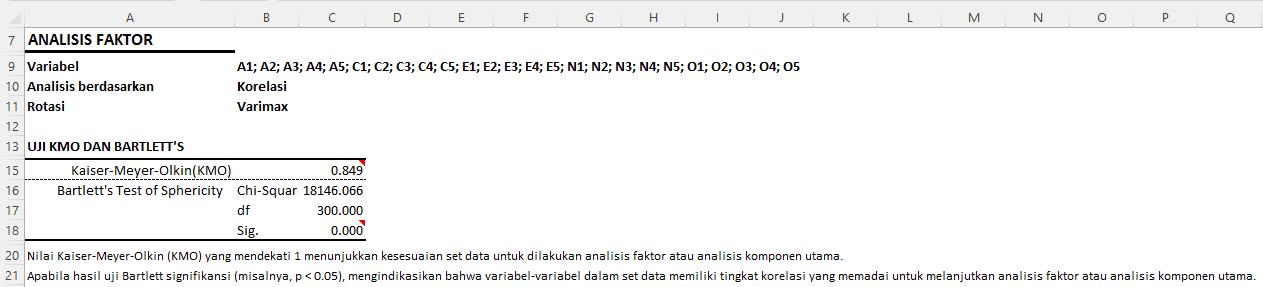
Uji Kaiser-Meyer-Olkin (KMO) dan Uji Bartlett's Test of Sphericity
Hasil analisis faktor ini telah melalui tahapan pengujian pra-analisis menggunakan uji Kaiser-Meyer-Olkin (KMO) dan Bartlett's Test of Sphericity.
Nilai Kaiser-Meyer-Olkin (KMO) sebesar 0.849. Nilai KMO berkisar antara 0 dan 1. Nilai yang lebih dekat ke 1 menunjukkan bahwa pola korelasi antar variabel cukup baik untuk analisis faktor. Dalam hal ini, KMO sebesar 0.849 menunjukkan bahwa dataset cocok untuk analisis faktor.
Uji Bartlett digunakan untuk menguji hipotesis nol bahwa matriks korelasi dalam populasi adalah matriks identitas, yang akan mengindikasikan bahwa variabel-variabel adalah tidak berkorelasi dalam populasi. Jika p-value (Significance, Sig.) lebih kecil dari 0.05, maka hipotesis nol ditolak dan dapat disimpulkan bahwa variabel-variabel berkorelasi cukup untuk analisis faktor. Dalam hal ini, nilai Sig. adalah 0.000, jadi hipotesis nol ditolak, dan analisis faktor bisa dilanjutkan karena variabel-variabel mempunyai tingkat korelasi yang memadai.
Jadi, berdasarkan hasil uji KMO dan Bartlett's Test, dapat disimpulkan bahwa dataset sangat cocok untuk dilakukan analisis faktor.
Tabel Matriks Korelasi

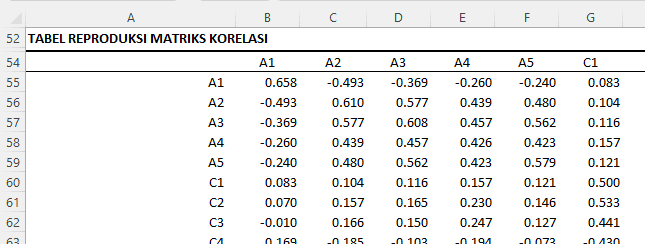
Tabel-tabel tersebut menunjukkan berbagai informasi tentang hubungan antara variabel dalam dataset:
Tabel Matriks Korelasi
Matriks korelasi ini menunjukkan hubungan antara setiap pasangan variabel. Nilainya berkisar dari -1 sampai 1, di mana -1 berarti korelasi negatif sempurna, 1 berarti korelasi positif sempurna, dan 0 berarti tidak ada korelasi.
Tabel Reproduksi Matriks Korelasi
Tabel ini menghasilkan estimasi dari matriks korelasi asli berdasarkan komponen utama yang diekstrak. Dalam tabel ini, setiap angka mewakili perkiraan nilai korelasi berdasarkan komponen utama.
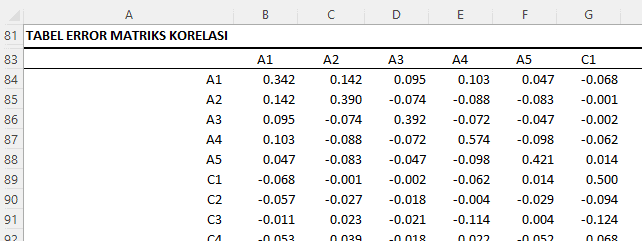
Tabel Error Matriks Korelasi
Tabel ini menunjukkan perbedaan antara matriks korelasi asli dan reproduksi, yang dapat memberi tahu kita sejauh mana model dapat mereproduksi korelasi asli. Nilai yang lebih rendah menunjukkan bahwa model kita melakukan pekerjaan yang baik dalam mereproduksi korelasi asli. Dalam kasus ini, tampaknya errornya relatif kecil, yang menunjukkan bahwa model melakukan pekerjaan yang cukup baik.
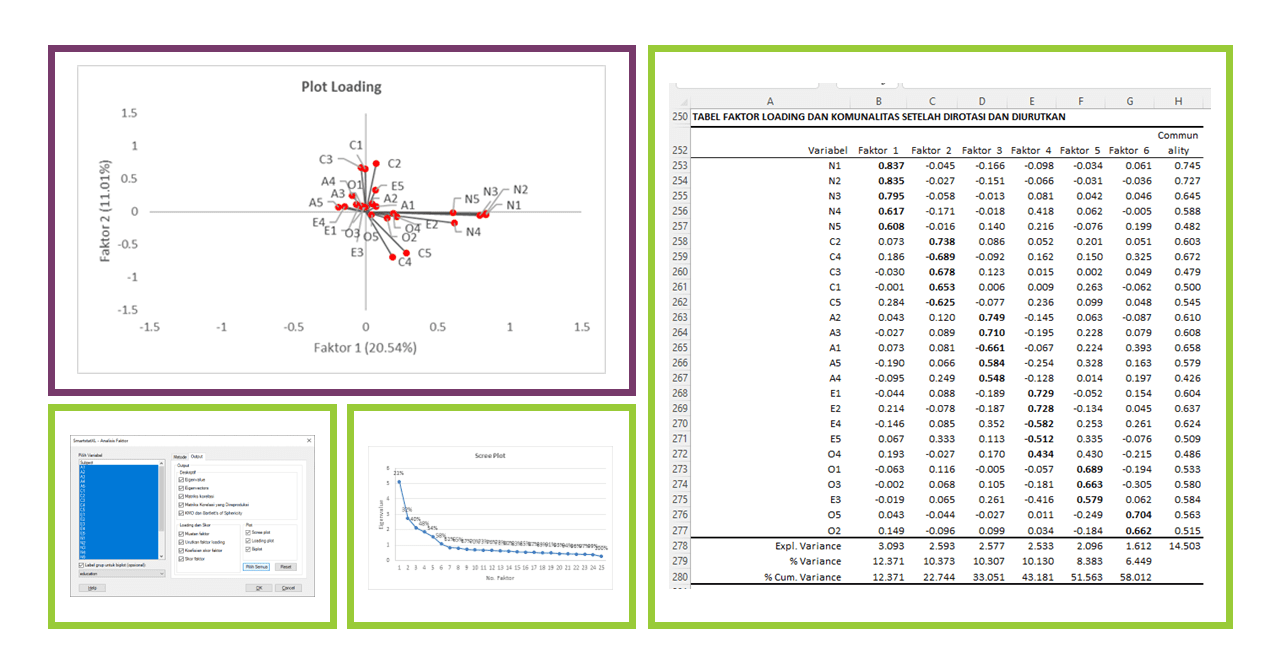
Eigenvalue dan Screeplot
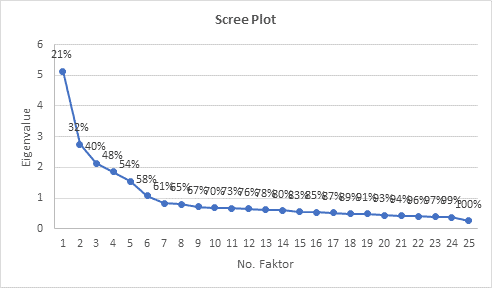
Tabel di atas menunjukkan jumlah variasi dalam data yang dijelaskan oleh masing-masing faktor. Variasi ini diukur dalam satuan yang disebut eigenvalue (nilai eigen). Eigenvalue adalah jumlah varians yang bisa dijelaskan oleh faktor tertentu. Semakin besar eigenvalue, semakin banyak varians yang dapat dijelaskan oleh faktor tersebut.
Komponen dalam tabel menunjukkan jumlah faktor yang dianalisis. Setiap faktor memiliki eigenvalue, proporsi variasi yang dijelaskan, dan proporsi kumulatif variasi yang dijelaskan. Misalnya, faktor pertama memiliki eigenvalue sebesar 5.134. Ini berarti faktor pertama bisa menjelaskan 20.5% dari total varians dalam dataset (proporsi). Jika kita melihat faktor kedua, faktor ini memiliki eigenvalue 2.752 dan menjelaskan tambahan 11.0% dari total varians. Jadi, jika kita melihat secara kumulatif, dua faktor pertama bisa menjelaskan 31.5% dari total varians dalam data.
Proses ini dilakukan untuk setiap faktor berikutnya. Dengan demikian, kita bisa melihat bahwa 25 faktor yang dianalisis menjelaskan 100% dari variasi dalam data (sebagaimana diindikasikan oleh proporsi kumulatif pada faktor 25).
Biasanya, kita hanya mempertahankan faktor yang memiliki eigenvalue lebih dari 1 (disebut aturan Kaiser), karena faktor tersebut dianggap bisa menjelaskan bagian signifikan dari varians. Dalam kasus ini, ada 6 faktor dengan eigenvalue lebih dari 1, yang berarti 6 faktor tersebut dianggap penting dan menjelaskan 58% dari total varians.
Tabel Eigenvector

Tabel eigenvector yang disajikan ini merupakan hasil dari analisis komponen utama (Principal Component Analysis, PCA) yang diaplikasikan pada dataset BFI. Nilai dalam tabel ini menunjukkan bobot yang ditentukan untuk setiap variabel dalam mengkonstruksi komponen utama atau faktor.
Dengan mengingat konsep dari model lima faktor kepribadian yang digunakan dalam studi ini (Kesepakatan/Agreeableness, Kepedulian/Conscientiousness, Ekstraversi, Neurotisme, dan Keterbukaan/Openness), kita bisa mencoba untuk menginterpretasikan hasil ini. Perlu diingat bahwa interpretasi ini cukup subjektif dan tergantung pada konteks penelitian:
- Komponen Utama 1 (PC1): Komponen ini tampaknya memiliki korelasi negatif yang signifikan dengan variabel A1 (Agreeableness), E1 (Extraversion), E2 (Extraversion), N1 (Neuroticism), N2 (Neuroticism), N4 (Neuroticism), dan N5 (Neuroticism). Dengan kata lain, individu dengan skor tinggi di PC1 cenderung memiliki skor rendah pada variabel-variabel tersebut. Sementara itu, skor positif yang signifikan terdapat pada variabel A2, A3, A4, A5 (Agreeableness), C1, C2, C3 (Conscientiousness), E3, E4, E5 (Extraversion), dan O3 (Openness). Artinya, individu dengan skor tinggi di PC1 cenderung memiliki skor tinggi pada variabel-variabel tersebut.
- Komponen Utama 2 (PC2): Komponen ini tampaknya paling berhubungan dengan faktor Neurotisme (N1, N2, N3, N4, dan N5) dengan hubungan positif yang kuat, berarti individu dengan skor tinggi di PC2 cenderung memiliki skor tinggi dalam Neurotisme. Selain itu, terdapat korelasi negatif yang signifikan dengan E1 (Extraversion), artinya individu dengan skor tinggi di PC2 cenderung memiliki skor rendah di E1.
- Komponen Utama 3 (PC3): Komponen ini tampaknya memiliki korelasi positif yang kuat dengan C1, C2, dan C3 (Conscientiousness) dan korelasi negatif dengan O2 dan O5 (Openness), A2, A3, dan A5 (Agreeableness), dan E4 (Extraversion).
- Komponen Utama 4 (PC4): Komponen ini memiliki korelasi positif yang kuat dengan O5 dan O2 (Openness) dan C3 (Conscientiousness), dan korelasi negatif dengan O1 dan O3 (Openness).
- Komponen Utama 5 (PC5): Komponen ini memiliki korelasi positif yang kuat dengan A2, A3, A4, A5 (Agreeableness) dan E1 dan E2 (Extraversion), dan korelasi negatif dengan A1 (Agreeableness).
- Komponen Utama 6 (PC6): Komponen ini memiliki korelasi positif yang kuat dengan A1 (Agreeableness), C4, dan C5 (Conscientiousness), dan O1, O2, dan O5 (Openness).
Setiap komponen utama ini mewakili kombinasi linear dari variabel-variabel yang ada dan bisa diartikan sebagai faktor-faktor laten yang mendasari dataset. Dalam konteks ini, faktor-faktor tersebut mungkin mencakup dimensi kepribadian yang tidak ditangkap secara langsung oleh skala yang digunakan dalam studi ini. Interpretasi spesifik tentang apa yang sebenarnya diwakili oleh masing-masing komponen utama akan memerlukan pemahaman yang lebih mendalam tentang konteks penelitian dan mungkin analisis tambahan.
Faktor Loading

Tabel ini menunjukkan nilai faktor loading dan komunalitas untuk setiap variabel pada setiap faktor. Faktor loading adalah korelasi antara variabel asli dan faktor. Faktor loading yang besar (baik positif atau negatif) menunjukkan bahwa variabel tersebut memiliki kontribusi yang besar terhadap faktor tersebut.
Interpretasi faktor dilakukan dengan melihat faktor loadings mana yang paling tinggi untuk setiap faktor. Misalnya, pada Faktor 1, variabel A5, A3, E4, dan A2 memiliki faktor loadings tertinggi, sementara pada Faktor 2, variabel N1, N2, dan N3 memiliki faktor loadings tertinggi. Hal ini menunjukkan bahwa Faktor 1 dan Faktor 2 masing-masing berkaitan erat dengan variabel-variabel tersebut.
Sementara itu, komunalitas untuk setiap variabel adalah jumlah kuadrat dari faktor loadings untuk variabel tersebut dan menggambarkan persentase varians dalam variabel yang dapat dijelaskan oleh faktor-faktor. Misalnya, komunalitas untuk variabel A1 adalah 0.658, yang berarti bahwa 65.8% varians dalam A1 dapat dijelaskan oleh enam faktor yang diidentifikasi.
Pada bagian bawah tabel, "Expl. Variance" menunjukkan jumlah variasi yang dijelaskan oleh setiap faktor, dan "% Variance" dan "% Cum. Variance" menunjukkan persentase variasi yang dijelaskan oleh setiap faktor dan jumlah kumulatifnya. Misalnya, Faktor 1 menjelaskan 20.5% variasi, dan Faktor 1 dan 2 bersama-sama menjelaskan 31.5% variasi.
Nilai-nilai ini menunjukkan bahwa model faktor ini cukup baik dalam menjelaskan variasi dalam variabel-variabel ini, meskipun ada beberapa varians yang masih belum dijelaskan. Keseluruhan variasi yang dijelaskan oleh model ini adalah 58.012%.
Pada akhirnya, interpretasi ini perlu ditinjau dengan konteks penelitian Kita untuk memastikan bahwa interpretasi ini masuk akal dan berguna dalam penelitian. Selain itu, nilai faktor loadings ini juga dapat membantu Kita memutuskan apakah harus menyimpan atau menghilangkan variabel tertentu atau faktor dalam analisis lebih lanjut, tergantung pada pertanyaan penelitian dan desain studi.
Rotasi Faktor Loading
Sebelum rotasi, faktor yang dihasilkan mungkin sulit untuk ditafsirkan, karena mereka cenderung memiliki banyak variabel dengan faktor loading yang tinggi, dan karena faktor tersebut biasanya tidak ortogonal (yaitu, faktor tidak bebas satu sama lain). Ini adalah hal yang biasa terjadi dalam analisis faktor dan bukanlah suatu masalah. Namun, untuk membuat interpretasi lebih mudah, kita biasanya melakukan rotasi pada faktor.
Rotasi tidak mengubah apa pun tentang variabel asli atau jumlah varians yang dijelaskan oleh faktor, tetapi mengubah faktor loading variabel pada setiap faktor. Tujuannya adalah untuk mencapai "struktur sederhana", di mana setiap variabel memiliki faktor loading yang tinggi pada satu faktor dan rendah pada faktor lainnya. Ada banyak metode rotasi, tetapi metode Varimax adalah salah satu yang paling umum digunakan. Setelah rotasi (dalam hal ini, dengan metode Varimax), struktur faktor biasanya lebih mudah ditafsirkan. Faktor loading yang tinggi untuk variabel pada suatu faktor menunjukkan bahwa variabel tersebut sangat berkaitan dengan faktor tersebut. Faktor loading yang rendah menunjukkan sebaliknya.
Perlu dicatat bahwa setelah rotasi, faktor biasanya tidak lagi berkorelasi satu sama lain (yaitu, mereka sekarang ortogonal), yang sering membuat interpretasi lebih mudah. Meskipun demikian, penting untuk diingat bahwa metode rotasi tertentu (misalnya, rotasi oblik) dapat menghasilkan faktor yang tidak ortogonal.
Berikut adalah tabel faktor loading setelah dirotasi dan diurutkan.

Tabel ini menunjukkan nilai loading faktor dan komunalitas untuk setiap variabel. Berdasarkan tabel hasil analisis faktor tersebut, kita bisa membuat beberapa interpretasi:
- Faktor 1 tampaknya mewakili variabel Neurotisme (N1 hingga N5). Ini bisa kita lihat dari nilai faktor loading yang tinggi pada variabel N1 hingga N5. Oleh karena itu, faktor ini bisa kita namai "Neurotisme".
- Faktor 2 tampaknya mewakili variabel Kepedulian (Conscientiousness, C1 hingga C5). Nilai faktor loading tertinggi berada pada variabel C2, C4, C3, C1, dan C5. Oleh karena itu, faktor ini bisa kita namai "Kepedulian".
- Faktor 3 tampaknya mewakili variabel Kesepakatan (Agreeableness, A1 hingga A5). Nilai faktor loading tertinggi berada pada variabel A2, A3, A1, A5, dan A4. Oleh karena itu, faktor ini bisa kita namai "Kesepakatan".
- Faktor 4 tampaknya mewakili variabel Ekstraversi (E1 hingga E5). Nilai faktor loading tertinggi berada pada variabel E1, E2, E4, dan E5. Oleh karena itu, faktor ini bisa kita namai "Ekstraversi".
- Faktor 5 tampaknya mewakili sebagian besar variabel Keterbukaan (Openness, O1 hingga O5) dan sedikit variabel Ekstraversi (E3). Nilai faktor loading tertinggi berada pada variabel O1, O3, dan E3. Oleh karena itu, faktor ini bisa kita namai "Keterbukaan".
- Faktor 6 tampaknya mewakili variabel O5 dan O2, tetapi nilai faktor loadingnya lebih rendah dibanding faktor-faktor lainnya. Oleh karena itu, interpretasi faktor ini mungkin kurang jelas atau faktor ini mungkin kurang penting dalam konteks dataset ini.
Secara keseluruhan, tabel ini mengindikasikan bahwa model faktor ini sukses dalam menemukan struktur faktor yang logis berdasarkan studi-studi sebelumnya tentang kepribadian, dan temuannya sejalan dengan struktur Big Five yang diusulkan, meski masih ada beberapa variabel yang tidak sejalan.
Dalam diskusi berikutnya, akan dilakukan analisis dengan memodifikasi model ekstraksi berdasarkan jumlah faktor yang telah ditentukan, yaitu 5 Faktor.
Plot Loading dan Biplot
Plot Loading
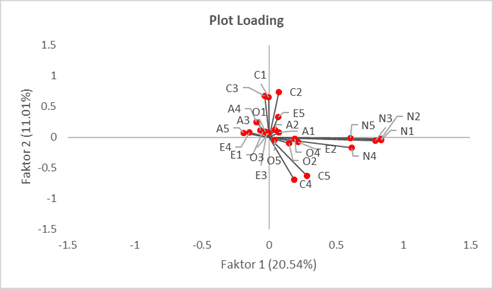
Plot loading adalah visualisasi dari komponen loading yang kita bicarakan sebelumnya. Plot loading menunjukkan berapa banyak setiap variabel asli berkontribusi pada komponen utama.
Pada sumbu horizontal, kita memiliki Faktor 1 yang menjelaskan 20.54% dari varians total, dan pada sumbu vertikal, kita memiliki Faktor 2 yang menjelaskan 11.01% dari varians total.
Biplot

Biplot adalah ekstensi dari plot loading, di mana data observasi juga ditampilkan dalam ruang dimensi yang lebih rendah. Biplot digunakan untuk visualisasi dari data multivariat, di mana baik variabel asli (dalam bentuk vektor) dan pengamatan individu ditampilkan. Dalam hal ini, selain loading untuk masing-masing variabel (sama seperti yang ditampilkan dalam plot loading), sebaran data observasi juga ditampilkan. Masing-masing titik pada plot mewakili satu pengamatan, dan posisi relatif dari titik-titik tersebut mencerminkan hubungan antara pengamatan tersebut dalam ruang dimensi yang lebih rendah yang dihasilkan oleh Analisis Faktor.
Biplot dapat membantu kita memahami bagaimana pengamatan berhubungan satu sama lain berdasarkan variabel asli, dan bagaimana variabel-variabel tersebut berkontribusi terhadap komponen utama.
Tabel Koefisien Skor Faktor
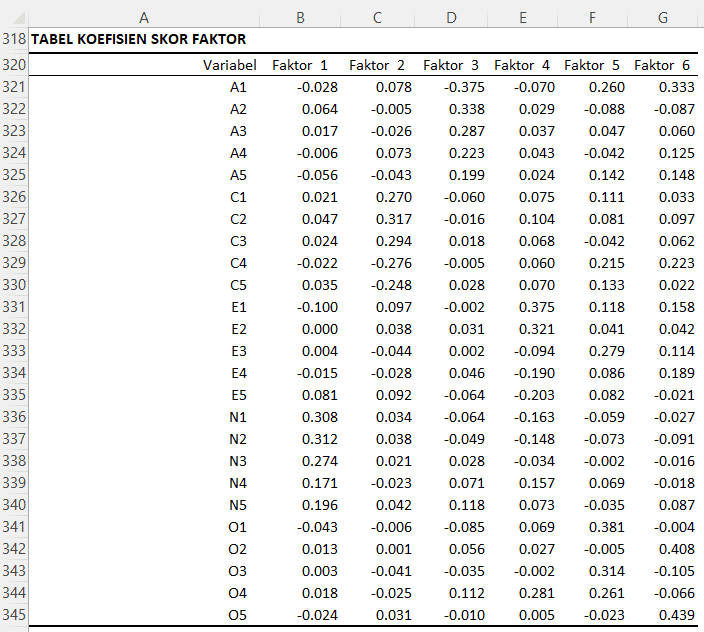
Tabel Koefisien Skor Faktor ini menunjukkan bagaimana skor untuk masing-masing faktor (dalam hal ini, Faktor 1 sd. Faktor 6) dihitung dari variabel asli. Nilai pada tabel ini adalah koefisien regresi dari masing-masing variabel asli pada komponen utama, yang berarti mereka menunjukkan berapa banyak perubahan dalam komponen utama yang diharapkan per unit perubahan dalam variabel asli, asumsikan semua variabel lainnya tetap. Secara umum, Tabel Koefisien Skor Komponen ini memberikan ringkasan tentang bagaimana variabel asli berkontribusi terhadap masing-masing komponen utama dan bagaimana skor komponen utama dihitung dari variabel asli.
Nilai dalam tabel ini adalah bobot atau beban faktor yang menunjukkan sejauh mana setiap variabel berkontribusi terhadap faktor yang mendasari. Bobot ini digunakan untuk menghitung skor faktor untuk setiap individu dalam sampel berdasarkan jawaban mereka pada item-item inventaris.
Interpretasi koefisien skor faktor mirip dengan interpretasi eigenvector dalam PCA. Namun, dalam konteks analisis faktor, bobot ini sering kali diinterpretasikan dalam hal "muatan" variabel pada faktor yang mendasari. Sebagai contoh, variabel dengan bobot faktor tinggi pada suatu faktor akan memiliki kontribusi yang besar terhadap skor faktor tersebut, dan oleh karena itu, cenderung mewakili konsep atau konstruksi yang sama.
Berikut ini adalah interpretasi beberapa faktor berdasarkan tabel di atas:
- Faktor 1: Faktor ini tampaknya paling berhubungan dengan variabel N1, N2, N3, N4, dan N5 (Neurotisme) dengan beban positif yang kuat, berarti individu dengan skor tinggi dalam faktor ini cenderung memiliki skor tinggi dalam Neurotisme.
- Faktor 2: Faktor ini tampaknya paling berhubungan dengan variabel C1, C2, dan C3 (Kepedulian/Conscientiousness) dengan beban positif yang kuat, dan variabel C4 dan C5 dengan beban negatif yang kuat. Artinya, individu dengan skor tinggi pada faktor ini cenderung memiliki skor tinggi dalam beberapa aspek Kepedulian dan skor rendah dalam aspek Kepedulian lainnya.
- Faktor 3: Faktor ini tampaknya memiliki korelasi positif dengan A2 dan A3 (Kesepakatan/Agreeableness), dan korelasi negatif dengan A1 dan O1 (Keterbukaan/Openness).
- Faktor 4: Faktor ini tampaknya memiliki korelasi positif dengan E1 dan E2 (Ekstraversi) dan O4 (Keterbukaan/Openness), dan korelasi negatif dengan E4 dan E5 (Ekstraversi).
- Faktor 5: Faktor ini tampaknya memiliki korelasi positif dengan E3 (Ekstraversi) dan O1, O3, dan O4 (Keterbukaan/Openness).
- Faktor 6: Faktor ini tampaknya memiliki korelasi positif yang kuat dengan O2 dan O5 (Keterbukaan/Openness) dan A1 (Kesepakatan/Agreeableness).
Setiap faktor ini mewakili dimensi laten yang berbeda dari kepribadian yang ditangkap oleh item-item inventaris. Interpretasi spesifik tentang apa yang sebenarnya diwakili oleh setiap faktor akan memerlukan pemahaman yang lebih mendalam tentang konteks penelitian dan mungkin analisis tambahan.
Tabel Skor Komponen
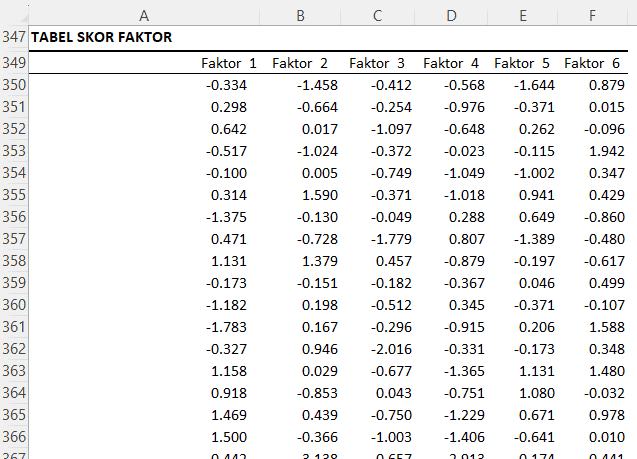
Tabel ini menampilkan skor faktor individu untuk setiap faktor. Skor faktor ini merupakan skor yang dihasilkan berdasarkan bobot atau koefisien skor faktor yang telah dihitung sebelumnya. Setiap baris dalam tabel ini mewakili seorang individu dalam sampel, dan setiap kolom mewakili faktor yang berbeda. Tabel Skor Faktor ini mewakili hasil akhir dari analisis faktor. Skor faktor ini mewakili sejauh mana setiap responden atau pengamatan dalam sampel berkaitan dengan faktor yang dihasilkan oleh analisis.
Dalam konteks analisis faktor kepribadian, skor faktor ini bisa diinterpretasikan sebagai ukuran setiap responden di sepanjang dimensi kepribadian yang mendasari. Misalnya, responden dengan skor tinggi pada faktor 1 mungkin memiliki tingkat neurotisisme yang tinggi, dan responden dengan skor rendah pada faktor 1 mungkin memiliki tingkat neurotisisme yang rendah (asumsi ini didasarkan pada interpretasi koefisien skor faktor dari pertanyaan sebelumnya).
Sebagai contoh, responden pertama memiliki skor -0.334 pada faktor 1, skor -1.458 pada faktor 2, dan seterusnya. Jika kita mengikuti interpretasi koefisien skor faktor dari pertanyaan sebelumnya, responden ini mungkin memiliki tingkat neurotisisme yang relatif rendah (berdasarkan skor negatif pada faktor 1) dan juga memiliki tingkat kepedulian yang rendah (berdasarkan skor negatif pada faktor 2). Dalam praktiknya, skor faktor ini dapat digunakan untuk melihat bagaimana individu menempatkan diri mereka dalam berbagai dimensi kepribadian yang telah diidentifikasi oleh analisis faktor. Selanjutnya, skor ini bisa digunakan untuk menghubungkan dimensi kepribadian ini dengan variabel lain, seperti perilaku, hasil, atau variabel demografis.
Hasil Analisis CFA (model ekstraksi berdasarkan jumlah faktor yang telah ditentukan, yaitu 5 Faktor)
Analisis faktor adalah teknik statistik yang digunakan untuk mengidentifikasi struktur laten, atau faktor, yang dapat menjelaskan korelasi antara variabel. Ada dua jenis utama analisis faktor, yaitu analisis faktor eksploratori (EFA) dan analisis faktor konfirmatori (CFA).
Dalam analisis faktor eksploratori (EFA), tujuannya adalah untuk mengeksplorasi struktur data dan menentukan jumlah faktor atau komponen utama yang ada di dalam data. Salah satu metode yang umum digunakan dalam EFA adalah ekstraksi berdasarkan nilai eigen, di mana faktor atau komponen yang memiliki nilai eigen lebih besar dari satu dianggap signifikan dan dipertahankan. Nilai eigen di sini merepresentasikan seberapa banyak varians dalam data yang dijelaskan oleh faktor atau komponen tersebut. Oleh karena itu, dengan metode ini, jumlah faktor atau komponen tidak ditentukan sebelumnya, tetapi dipilih berdasarkan hasil analisis.
Sebaliknya, dalam analisis faktor konfirmatori (CFA), tujuannya adalah untuk menguji apakah struktur faktor yang dihipotesiskan atau diusulkan sebelumnya sesuai dengan data. Dengan kata lain, kita memiliki teori atau model yang spesifik tentang struktur faktor, dan kita ingin menguji model tersebut menggunakan data. Dalam konteks ini, jumlah faktor atau komponen ditentukan sebelumnya, berdasarkan model atau teori yang diusulkan. Dalam kasus ini, model yang diusulkan memiliki lima faktor atau komponen.
Jadi, pada dasarnya, proses yang Kita lakukan adalah mulai dari EFA, di mana Kita mengeksplorasi data dan menentukan bahwa ada lima faktor atau komponen yang signifikan berdasarkan nilai eigen. Kemudian beralih ke CFA, di mana Kita menguji model dengan lima faktor ini, dan mendapatkan hasil yang menunjukkan bahwa model tersebut cukup baik dalam menjelaskan data.
Pada kotak dialog berikut, kita pilih opsi model ekstraksi berdasarkan banyaknya faktor tetap (5 Faktor yang sudah ditentukan sebelumnya)
Faktor Loading

Skor loading faktor pada tabel ini dapat diinterpretasikan sebagai korelasi antara item dan faktor yang bersangkutan. Nilai yang lebih tinggi menunjukkan korelasi yang lebih kuat. Misalnya, variabel N1 memiliki skor loading faktor sebesar 0.806 pada faktor 1, yang berarti variabel N1 memiliki korelasi yang sangat kuat dengan faktor 1. Berdasarkan informasi yang disediakan, faktor 1 mungkin merujuk kepada "Neuroticism".
Komunalitas (Communality) adalah proporsi varian dalam setiap variabel yang dapat dijelaskan oleh faktor-faktor yang ditemukan. Misalnya, komunalitas untuk variabel N1 adalah 0.710, yang berarti sekitar 71% dari varian dalam N1 dapat dijelaskan oleh faktor-faktor yang ditemukan.
Berdasarkan tabel yang sudah dirotasi varimax tersebut, terlihat bahwa variabel-variabel dari setiap faktor kepribadian (Neuroticism, Extraversion, Conscientiousness, Agreeableness, dan Openness) cenderung memiliki skor loading faktor yang lebih tinggi pada faktor yang bersesuaian. Misalnya:
- Faktor 1 memiliki skor loading tinggi untuk variabel N1-N5, yang merupakan indikator dari Neuroticism. Ini berarti faktor 1 mungkin mewakili Neuroticism.
- Faktor 2 memiliki skor loading tinggi untuk variabel E2, E4, E1, E3, dan E5, yang merupakan indikator dari Extraversion.
- Faktor 3 memiliki skor loading tinggi untuk variabel C2, C4, C3, C1, dan C5, yang merupakan indikator dari Conscientiousness.
- Faktor 4 memiliki skor loading tinggi untuk variabel A2, A3, A1, A5, dan A4, yang merupakan indikator dari Agreeableness.
- Faktor 5 memiliki skor loading tinggi untuk variabel O5, O3, O2, O1, dan O4, yang merupakan indikator dari Openness.
Pada dasarnya, hasil rotasi varimax ini menunjukkan bahwa faktor yang diekstraksi memiliki interpretasi yang jelas dan konsisten dengan lima dimensi kepribadian yang diharapkan (Neuroticism, Extraversion, Conscientiousness, Agreeableness, dan Openness). Variabel-variabel yang berkaitan dengan dimensi yang sama cenderung memiliki skor loading tinggi pada faktor yang sama.
Expl. Variance menggambarkan berapa banyak varian total yang dijelaskan oleh masing-masing faktor, sedangkan % Variance menunjukkan persentase varian yang dijelaskan oleh masing-masing faktor. % Cum. Variance menunjukkan akumulasi persentase varian yang dijelaskan oleh faktor-faktor. Misalnya, faktor 1 menjelaskan sekitar 12.738% dari varian total dan faktor 2 menjelaskan sekitar 12.400% varian tambahan, sehingga kedua faktor tersebut bersama-sama menjelaskan sekitar 25.139% dari varian total. Secara keseluruhan, kelima faktor menjelaskan sekitar 53.718% dari varian total.
Kesimpulan
Pada tutorial ini, berikut adalah beberapa poin penting yang dapat disimpulkan:
- Analisis faktor adalah teknik statistik yang digunakan untuk mengidentifikasi struktur laten di balik kumpulan variabel, dengan tujuan mengurangi dimensi data. Pada kasus ini, analisis faktor digunakan untuk mengidentifikasi struktur faktor dari item-item penilaian kepribadian berdasarkan model Big Five Personality Traits.
- Dalam analisis faktor, ada dua metode ekstraksi yang berbeda: Ekstraksi berdasarkan eigenvalue dan ekstraksi berdasarkan faktor tetap. Pada kasus ini, keduanya digunakan, yang mungkin mengindikasikan perbedaan antara Exploratory Factor Analysis (EFA) dan Confirmatory Factor Analysis (CFA).
- Hasil dari analisis faktor sebelum rotasi dan setelah rotasi (dengan varimax) telah diberikan dan diinterpretasikan. Faktor rotasi memudahkan interpretasi hasil, dengan memaksimalkan faktor loading pada faktor tertentu dan meminimalkan faktor loading pada faktor lain.
- Hasil analisis faktor setelah rotasi menunjukkan struktur faktor yang masuk akal dan konsisten dengan model Big Five Personality Traits yang diusulkan, meskipun ada beberapa variabel yang tidak sepenuhnya konsisten.
- Dalam konteks ini, Principal Component Analysis (PCA) juga digunakan sebagai metode ekstraksi, yang melibatkan pencarian vektor dan nilai eigen dari matriks kovariansi atau korelasi.
Secara keseluruhan, analisis faktor telah berhasil digunakan untuk mengidentifikasi struktur faktor dari item-item penilaian kepribadian dan memberikan wawasan yang berharga tentang hubungan antar variabel.