Analisis klaster adalah teknik statistik yang digunakan untuk mengelompokkan objek atau kasus ke dalam beberapa grup berdasarkan informasi yang ditemukan dalam data yang menggambarkan objek dan hubungan mereka. Tujuan utama dari analisis klaster adalah untuk mengidentifikasi struktur atau segmen dalam data.
Salah satu metode yang paling populer dan sederhana dalam analisis klaster adalah algoritma K‑Means. Algoritma ini dinamakan "K-Means" karena proses pengelompokan data dilakukan dengan cara menghitung rata-rata (mean) dari setiap klaster. Nilai 'K' dalam K-Means merujuk pada jumlah klaster yang akan dibuat dari data.
Secara garis besar, proses kerja algoritma K-Means adalah sebagai berikut:
- Menentukan jumlah klaster yang diinginkan (K).
- Menentukan pusat klaster secara acak.
- Menghitung jarak setiap data ke pusat klaster.
- Memasukkan data ke dalam klaster dengan jarak terdekat.
- Menghitung ulang pusat klaster berdasarkan anggota-anggotanya.
- Mengulangi langkah 3 hingga 5 sampai pusat klaster tidak berubah lagi atau sampai iterasi maksimal tercapai.
Metode ini sangat efektif dalam menangani data berukuran besar dan dapat menghasilkan klaster yang solid. Namun, K-Means juga memiliki beberapa keterbatasan, seperti sensitivitas terhadap inisialisasi awal dan sulit menangani klaster yang tidak berbentuk bola atau memiliki varians yang berbeda. Oleh karena itu, penting untuk memahami data dan karakteristiknya sebelum memilih metode ini untuk analisis klaster.
Dalam analisis yang akan kita lakukan, kita akan menjelaskan lebih detail tentang metode K-Means, langkah-langkahnya, serta bagaimana melakukan interpretasi hasil yang diperoleh. Selanjutnya, kita juga akan membahas beberapa teknik untuk mengatasi keterbatasan algoritma K-Means.
Contoh Kasus
Dalam tutorial analisis klaster ini, kita akan menggunakan dataset Iris, dataset yang sering digunakan dalam berbagai studi ilmiah dan dikenal dalam literatur machine learning. Dataset ini terdiri dari 150 sampel dari tiga spesies bunga iris, yaitu Iris setosa, Iris virginica, dan Iris versicolor. Dari setiap sampel, diukur empat fitur yang mencakup panjang dan lebar sepal (bagian luar bunga), serta panjang dan lebar petal (daun bunga).
Untuk tutorial ini, kita tidak akan menggunakan seluruh sampel dari dataset tersebut. Kita hanya akan mengambil sampel acak sebanyak 35 sampel dari 150 sampel untuk mempermudah dan mempercepat proses belajar.
Tujuan dari tutorial ini adalah untuk mengaplikasikan algoritma K-Means pada dataset Iris ini dan menginterpretasikan hasil yang diperoleh. Melalui tutorial ini, kita juga akan membahas bagaimana K-Means bekerja, bagaimana cara menggunakannya, dan juga tantangan apa saja yang mungkin kita hadapi dalam proses ini.
Dengan memahami prinsip kerja algoritma K-Means dan bagaimana mengaplikasikannya pada dataset nyata seperti Iris, diharapkan kita dapat memahami lebih dalam lagi mengenai analisis klaster dan bagaimana menggunakannya dalam penelitian atau proyek data science kita. Selanjutnya, kita akan memulai dengan tahap pertama analisis kita, yaitu mempersiapkan dan memahami data yang akan kita gunakan.
Iris Dataset: Originally published at UCI Machine Learning Repository
Iris Dataset, this small dataset from 1936 is often used for testing out machine learning algorithms and visualizations. The Iris data set is a classification dataset that contains three classes of 50 instances each, where each class refers to a type of iris plant. The three classes in the Iris dataset are: Setosa, Versicolor, Virginica. Each row of the table represents an iris flower, including its species and dimensions of its botanical parts, sepal length, sepal width, petal length and petal width (in centimeters).
No | Sepal length | Sepal width | Petal length | Petal width | Species |
11 | 5.4 | 3.7 | 1.5 | 0.2 | Setosa |
14 | 4.3 | 3 | 1.1 | 0.1 | Setosa |
20 | 5.1 | 3.8 | 1.5 | 0.3 | Setosa |
24 | 5.1 | 3.3 | 1.7 | 0.5 | Setosa |
26 | 5 | 3 | 1.6 | 0.2 | Setosa |
27 | 5 | 3.4 | 1.6 | 0.4 | Setosa |
28 | 5.2 | 3.5 | 1.5 | 0.2 | Setosa |
31 | 4.8 | 3.1 | 1.6 | 0.2 | Setosa |
39 | 4.4 | 3 | 1.3 | 0.2 | Setosa |
44 | 5 | 3.5 | 1.6 | 0.6 | Setosa |
47 | 5.1 | 3.8 | 1.6 | 0.2 | Setosa |
54 | 5.5 | 2.3 | 4 | 1.3 | Versicolor |
62 | 5.9 | 3 | 4.2 | 1.5 | Versicolor |
67 | 5.6 | 3 | 4.5 | 1.5 | Versicolor |
73 | 6.3 | 2.5 | 4.9 | 1.5 | Versicolor |
81 | 5.5 | 2.4 | 3.8 | 1.1 | Versicolor |
83 | 5.8 | 2.7 | 3.9 | 1.2 | Versicolor |
86 | 6 | 3.4 | 4.5 | 1.6 | Versicolor |
93 | 5.8 | 2.6 | 4 | 1.2 | Versicolor |
96 | 5.7 | 3 | 4.2 | 1.2 | Versicolor |
97 | 5.7 | 2.9 | 4.2 | 1.3 | Versicolor |
100 | 5.7 | 2.8 | 4.1 | 1.3 | Versicolor |
104 | 6.3 | 2.9 | 5.6 | 1.8 | Virginica |
107 | 4.9 | 2.5 | 4.5 | 1.7 | Virginica |
112 | 6.4 | 2.7 | 5.3 | 1.9 | Virginica |
115 | 5.8 | 2.8 | 5.1 | 2.4 | Virginica |
121 | 6.9 | 3.2 | 5.7 | 2.3 | Virginica |
124 | 6.3 | 2.7 | 4.9 | 1.8 | Virginica |
127 | 6.2 | 2.8 | 4.8 | 1.8 | Virginica |
131 | 7.4 | 2.8 | 6.1 | 1.9 | Virginica |
138 | 6.4 | 3.1 | 5.5 | 1.8 | Virginica |
140 | 6.9 | 3.1 | 5.4 | 2.1 | Virginica |
145 | 6.7 | 3.3 | 5.7 | 2.5 | Virginica |
146 | 6.7 | 3 | 5.2 | 2.3 | Virginica |
148 | 6.5 | 3 | 5.2 | 2 | Virginica |
Author: R.A. Fisher (1936)
Source: UCI Machine Learning Repository
Langkah-langkah Analisis K-Means:
- Aktifkan lembar kerja (Sheet) yang akan dianalisis.
- Tempatkan kursor pada Dataset (untuk membuat Dataset, lihat cara Persiapan Data).
- Apabila sel aktif (Active Cell) tidak berada pada Dataset, SmartstatXL otomatis akan mencoba menentukan Dataset secara otomatis.
- Aktifkan Tab SmartstatXL
- Klik Menu Multivariate > Analisis K-Means.

- SmartstatXL akan menampilkan kotak dialog untuk memastikan apakah Dataset sudah benar atau belum (biasanya alamat sel Dataset sudah otomatis dipilih dengan benar).

- Apabila sudah benar, Klik Tombol Selanjutnya
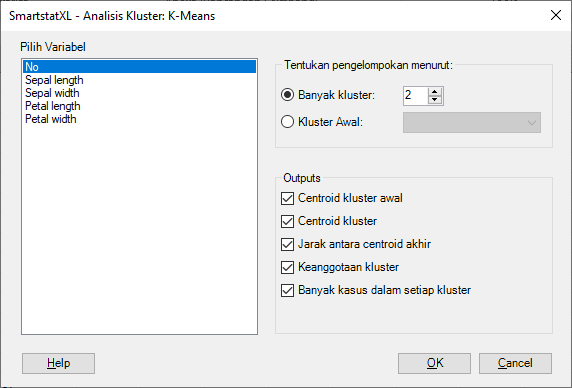
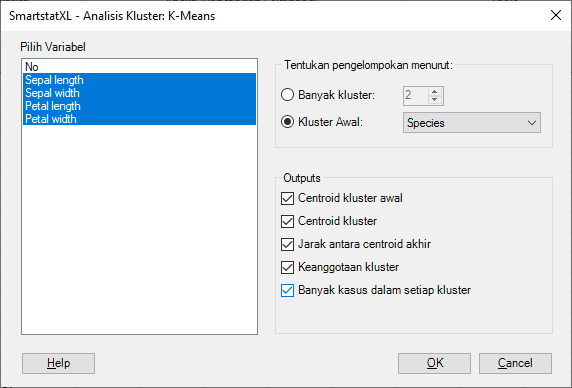
- Selanjutnya akan tampil Kotak Dialog Analisis K-Means:

- Pilih Variabel, Penentuan Klaster, dan Output. Pada contoh kasus ini kita tentukan:
- Variabel: Sepal length, Sepal width, Petal length, dan Petal width
- Pengelompokan: Kluster Awal
- Label Observasi: Species
Selengkapnya bisa dilihat pada tampilan kotak dialog berikut:
Pengelompokan
Terdapat dua opsi pengelompokan dalam analisis klaster menggunakan K-Means:
- Mengklasifikasikan Berdasarkan Banyak Klaster: Opsi ini cocok digunakan jika kita tidak memiliki referensi awal untuk pengelompokan data. Dalam konteks kita, karena kita memiliki pengetahuan sebelumnya bahwa dataset terdiri dari tiga spesies, kita dapat menentukan jumlah klaster, yaitu 3.
- Menggunakan Klaster Awal: Dalam dataset kita, ada kolom 'Spesies' yang dapat dijadikan acuan untuk mengelompokkan dataset Iris.
Pada tutorial ini, kita akan mengatur pengelompokan berdasarkan klaster awal, yaitu tiga spesies Iris.
- Pilih output Analisis K-Means seperti pada tampilan di atas.
- Tekan tombol OK untuk membuat outputnya dalam Lembar Output

Hasil Analisis
Informasi K-Means.
Berdasarkan hasil analisis dengan menggunakan metode K-Means, informasi awal yang kita peroleh adalah sebagai berikut:
Metode Analisis: K-Means
Variabel yang digunakan dalam analisis ini meliputi: Panjang Sepal (Sepal length), Lebar Sepal (Sepal width), Panjang Petal (Petal length), dan Lebar Petal (Petal width). Keempat variabel ini digunakan untuk membentuk klaster dalam analisis.
Untuk klaster awal, kita menggunakan informasi spesies dari dataset. Klaster 1 merujuk kepada spesies Setosa, Klaster 2 merujuk kepada spesies Versicolor, dan Klaster 3 merujuk kepada spesies Virginica.
Ini merupakan tahap awal dari analisis kita. Langkah berikutnya akan melibatkan penggunaan metode K-Means untuk mengelompokkan data berdasarkan keempat variabel yang telah ditentukan. Kemudian, kita akan melihat bagaimana setiap sampel dikelompokkan dan membandingkannya dengan klaster awal berdasarkan spesies.
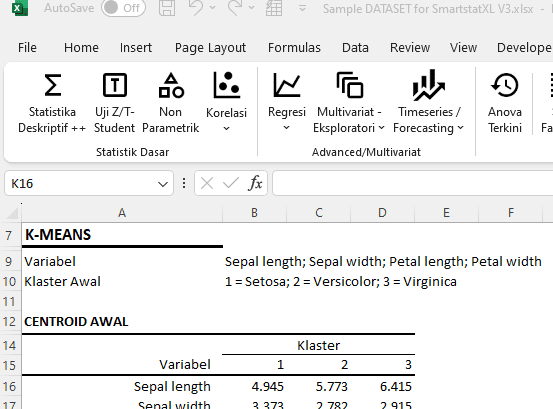
Tabel Sentroid Klaster Awal
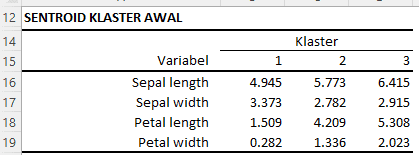
Output yang ditampilkan menggambarkan nilai centroid awal untuk setiap klaster. Dalam konteks algoritma K-Means, centroid merupakan pusat dari sebuah klaster. Nilai ini dihitung berdasarkan rata-rata dari setiap dimensi dalam klaster tersebut.
Berikut ini interpretasi dari output tersebut:
- Klaster 1, yang merujuk kepada spesies Setosa, memiliki centroid dengan nilai Sepal length 4.945, Sepal width 3.373, Petal length 1.509, dan Petal width 0.282. Nilai-nilai ini merepresentasikan karakteristik rata-rata dari bunga Iris spesies Setosa dalam dataset kita.
- Klaster 2, yang merujuk kepada spesies Versicolor, memiliki centroid dengan nilai Sepal length 5.773, Sepal width 2.782, Petal length 4.209, dan Petal width 1.336. Nilai-nilai ini merepresentasikan karakteristik rata-rata dari bunga Iris spesies Versicolor dalam dataset kita.
- Klaster 3, yang merujuk kepada spesies Virginica, memiliki centroid dengan nilai Sepal length 6.415, Sepal width 2.915, Petal length 5.308, dan Petal width 2.023. Nilai-nilai ini merepresentasikan karakteristik rata-rata dari bunga Iris spesies Virginica dalam dataset kita.
Dengan melihat nilai centroid ini, kita bisa mendapatkan pemahaman awal mengenai karakteristik setiap klaster. Misalnya, klaster 1 (Setosa) memiliki Sepal length dan Petal length yang lebih pendek dibandingkan dengan klaster lain, sementara klaster 3 (Virginica) memiliki Sepal length, Petal length, dan Petal width yang lebih panjang dibandingkan dengan klaster lain.
Perlu dicatat bahwa ini hanyalah titik awal dari analisis kita. Selanjutnya, kita akan menjalankan algoritma K-Means, dan centroid ini kemungkinan akan berubah seiring berjalannya iterasi.
Tabel Sentroid Klaster Akhir
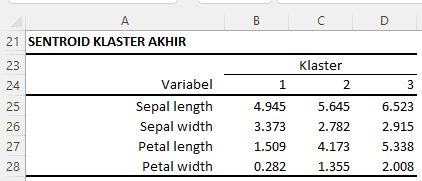
Output tersebut menunjukkan nilai centroid final setelah algoritma K-Means selesai dijalankan. Nilai centroid ini merepresentasikan titik pusat dari setiap klaster pada akhir proses pengelompokan.
Berikut ini interpretasi dari output tersebut:
- Klaster 1, yang merujuk kepada spesies Setosa, memiliki centroid akhir dengan nilai Sepal length 4.945, Sepal width 3.373, Petal length 1.509, dan Petal width 0.282. Ini menunjukkan bahwa karakteristik rata-rata dari klaster yang mewakili spesies Setosa relatif stabil dan tidak mengalami perubahan signifikan dari centroid awal ke centroid final.
- Klaster 2, yang merujuk kepada spesies Versicolor, memiliki centroid akhir dengan nilai Sepal length 5.645, Sepal width 2.782, Petal length 4.173, dan Petal width 1.355. Jika dibandingkan dengan centroid awal, kita melihat ada sedikit pergeseran dalam karakteristik rata-rata dari klaster ini, khususnya pada nilai Sepal length dan Petal width.
- Klaster 3, yang merujuk kepada spesies Virginica, memiliki centroid akhir dengan nilai Sepal length 6.523, Sepal width 2.915, Petal length 5.338, dan Petal width 2.008. Seperti klaster 2, ada sedikit perubahan dalam karakteristik rata-rata dari klaster ini, terutama pada nilai Sepal length dan Petal length.
Perubahan nilai centroid dari awal hingga akhir proses ini menunjukkan bagaimana algoritma K-Means bekerja dalam menyesuaikan dan memperbarui klaster berdasarkan karakteristik data. Centroid final ini sekarang mewakili karakteristik klaster setelah proses K-Means selesai, dan dapat digunakan untuk memahami struktur data kita dan melakukan prediksi atau analisis lebih lanjut.
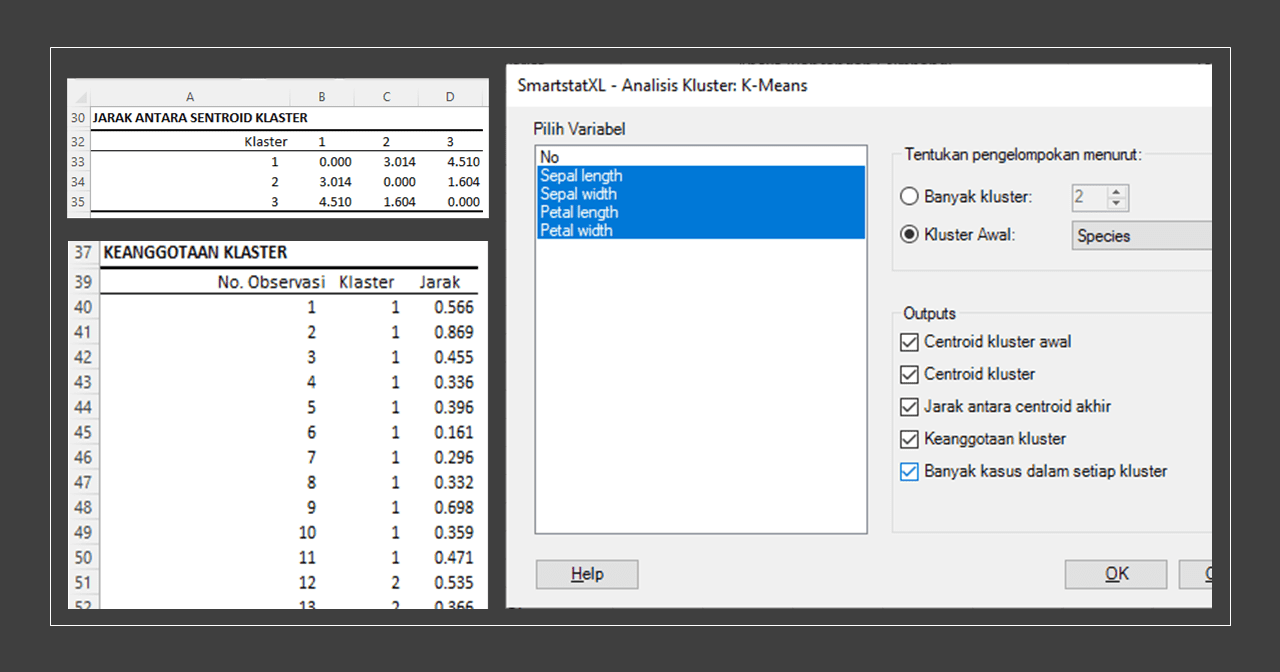
Jarak Antara Sentroid Klaster
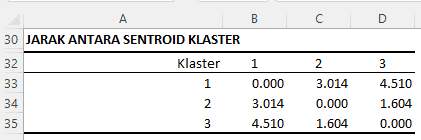
Output yang ditampilkan adalah jarak antara centroid dari setiap klaster. Dalam konteks algoritma K-Means, jarak antara centroid ini bisa memberikan gambaran seberapa "jauh" setiap klaster satu sama lain dalam ruang dimensi data kita.
Berikut interpretasinya:
- Klaster 1, yang merujuk kepada spesies Setosa, memiliki jarak 0 dengan dirinya sendiri (sebagai acuan), jarak 3.014 terhadap klaster 2 (Versicolor), dan jarak 4.510 terhadap klaster 3 (Virginica). Ini berarti klaster 1 relatif lebih dekat dengan klaster 2 daripada dengan klaster 3.
- Klaster 2, yang merujuk kepada spesies Versicolor, memiliki jarak 0 dengan dirinya sendiri (sebagai acuan), jarak 3.014 terhadap klaster 1 (Setosa), dan jarak 1.604 terhadap klaster 3 (Virginica). Ini berarti klaster 2 relatif lebih dekat dengan klaster 3 daripada dengan klaster 1.
- Klaster 3, yang merujuk kepada spesies Virginica, memiliki jarak 0 dengan dirinya sendiri (sebagai acuan), jarak 4.510 terhadap klaster 1 (Setosa), dan jarak 1.604 terhadap klaster 2 (Versicolor). Ini berarti klaster 3 relatif lebih dekat dengan klaster 2 daripada dengan klaster 1.
Jarak antara centroid ini penting untuk dimengerti karena bisa memberikan gambaran seberapa baik pengelompokan kita. Jika jarak antar klaster cukup besar, itu berarti setiap klaster cukup jelas terpisah dan tidak tumpang tindih, yang biasanya menunjukkan pengelompokan yang baik. Di sisi lain, jika jarak antar klaster kecil, maka mungkin ada ketidakjelasan atau tumpang tindih antara klaster, yang bisa menunjukkan bahwa model kita mungkin perlu disesuaikan atau ditingkatkan.
Keanggotaan Klaster
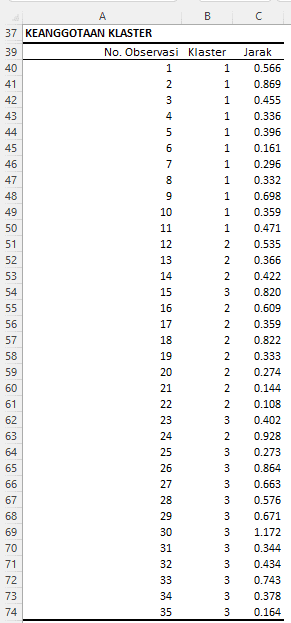
Output yang ditampilkan memberikan informasi mengenai keanggotaan setiap observasi dalam klaster, serta jarak setiap observasi ke centroid dari klaster yang bersangkutan.
- Observasi 1 hingga 11 diklasifikasikan dalam klaster 1, yang merujuk kepada spesies Setosa. Jarak setiap observasi ini terhadap centroid klaster 1 berkisar antara 0.161 hingga 0.869. Klasifikasi ini sudah tepat dan sesuai dengan spesies asli dari observasi tersebut.
- Observasi 12 hingga 22 diklasifikasikan dalam klaster 2, yang merujuk kepada spesies Versicolor. Jarak setiap observasi ini terhadap centroid klaster 2 berkisar antara 0.108 hingga 0.928. Namun, terdapat satu kesalahan klasifikasi di sini: Observasi 15, yang seharusnya merupakan spesies Versicolor, malah diklasifikasikan ke dalam klaster 3 (Virginica).
- Observasi 23 hingga 35 diklasifikasikan dalam klaster 3, yang merujuk kepada spesies Virginica. Jarak setiap observasi ini terhadap centroid klaster 3 berkisar antara 0.164 hingga 1.172. Di sini juga terdapat satu kesalahan klasifikasi: Observasi 24, yang seharusnya merupakan spesies Virginica, malah diklasifikasikan ke dalam klaster 2 (Versicolor).
Kesalahan dalam klasifikasi ini bisa disebabkan oleh berbagai hal, termasuk variabilitas alamiah dalam data atau batasan dari algoritma K-Means itu sendiri. Meskipun demikian, hasil klasifikasi secara umum masih cukup baik, dengan sebagian besar observasi diklasifikasikan ke dalam klaster yang benar. Hal ini menunjukkan bahwa algoritma K-Means cukup efektif dalam mengidentifikasi struktur klaster dalam data Iris ini.
Namun, perlu diperhatikan bahwa meskipun K-Means dapat memberikan hasil yang baik dalam banyak kasus, algoritma ini bukanlah pendekatan yang sempurna dan mungkin tidak selalu berhasil dalam mengidentifikasi klaster dengan benar, terutama dalam kasus di mana klaster tidak berbentuk bola atau ketika klaster memiliki densitas yang sangat berbeda. Oleh karena itu, selalu penting untuk memahami batasan algoritma ini dan mempertimbangkan penggunaan teknik lain atau penyesuaian algoritma jika diperlukan.
Ringkasan Banyak Pengamatan

Output ini memberikan informasi tentang jumlah pengamatan atau observasi dalam setiap klaster.
Berikut adalah interpretasinya:
- Klaster 1, yang merujuk kepada spesies Setosa, memiliki 11 observasi. Ini berarti bahwa dari total pengamatan, 11 di antaranya diklasifikasikan ke dalam klaster 1.
- Klaster 2, yang merujuk kepada spesies Versicolor, juga memiliki 11 observasi. Ini berarti bahwa dari total pengamatan, 11 di antaranya diklasifikasikan ke dalam klaster 2.
- Klaster 3, yang merujuk kepada spesies Virginica, memiliki 13 observasi. Ini berarti bahwa dari total pengamatan, 13 di antaranya diklasifikasikan ke dalam klaster 3.
Secara keseluruhan, penyebaran observasi antara klaster tampaknya cukup seimbang, dengan klaster 3 memiliki sedikit lebih banyak observasi dibandingkan dua klaster lainnya. Ini menunjukkan bahwa algoritma K-Means berhasil membagi data ke dalam klaster dengan jumlah yang relatif seimbang.
Namun, berdasarkan interpretasi sebelumnya, kita juga mengetahui bahwa ada beberapa observasi yang tidak diklasifikasikan dengan benar. Observasi 15 seharusnya berada dalam klaster 2 (Versicolor), namun diklasifikasikan ke dalam klaster 3 (Virginica). Sebaliknya, observasi 24 seharusnya berada dalam klaster 3 (Virginica), namun diklasifikasikan ke dalam klaster 2 (Versicolor). Ini menggambarkan bahwa meskipun algoritma K-Means cukup efektif, masih ada ruang untuk peningkatan dalam klasifikasi ini.
Kesimpulan
Berikut adalah kesimpulan dari analisis klaster menggunakan metode K-Means pada dataset Iris:
- Metode K-Means cukup efektif dalam mengidentifikasi dan membedakan tiga spesies Iris berdasarkan fitur-fitur seperti panjang dan lebar sepal, serta panjang dan lebar petal.
- Dalam analisis ini, K-Means berhasil membagi 35 sampel Iris ke dalam tiga klaster dengan sebaran yang cukup seimbang: 11 observasi dalam klaster 1 (Setosa), 11 observasi dalam klaster 2 (Versicolor), dan 13 observasi dalam klaster 3 (Virginica).
- Meski demikian, terdapat sedikit kesalahan dalam klasifikasi. Observasi 15, yang seharusnya masuk klaster 2 (Versicolor), justru masuk ke dalam klaster 3 (Virginica). Hal ini menunjukkan bahwa algoritma K-Means, meski cukup efektif, masih memiliki ruang untuk peningkatan.
- Kesalahan klasifikasi dapat disebabkan oleh berbagai faktor, termasuk variabilitas alamiah dalam data atau batasan algoritma K-Means itu sendiri.
- Untuk mengatasi batasan ini, peneliti perlu mempertimbangkan penggunaan teknik lain atau melakukan penyesuaian pada algoritma jika diperlukan. Misalnya, dapat menggunakan teknik klasterisasi lainnya seperti DBSCAN atau Hierarchical Clustering, atau melakukan tuning parameter pada algoritma K-Means.
Secara keseluruhan, analisis ini memberikan wawasan berharga tentang bagaimana K-Means dapat digunakan untuk mengidentifikasi dan mengklasifikasikan spesies Iris berdasarkan fitur-fitur mereka. Meski ada beberapa keterbatasan, K-Means tetap menjadi metode yang berguna dan efisien dalam analisis klaster.