SmartstatXL adalah salah satu Excel Add-In yang memungkinkan pengguna untuk melakukan analisis regresi, sebuah metode pemodelan hubungan antara variabel bebas (independen) dan variabel terikat (dependen). Salah satu tipe regresi yang dapat dianalisis dengan SmartstatXL adalah Regresi Linier Sederhana.
Analisis regresi linier sederhana digunakan sebagai alat inferensi statistik untuk menentukan pengaruh variabel bebas terhadap variabel terikat. Bentuk persamaannya adalah:
$$Y = {\beta _0} + \;{\beta _1}{X_1} + \varepsilon $$
Dalam analisis ini, hubungan antara variabel bersifat linier, yang berarti perubahan pada variabel X akan diikuti oleh perubahan pada variabel Y secara proporsional. Sebagai kontras, dalam hubungan non-linier, perubahan variabel X tidak selalu diikuti dengan perubahan variabel Y secara proporsional.
Fitur unggulan analisis regresi linier sederhana dengan SmartstatXL meliputi:
- Perhitungan data hilang.
- Diagnostik Regresi: Uji Normalitas, Uji Heteroskedastisitas, Plot Residual, dan Transformasi Box-Cox.
- Identifikasi dan penggantian data pencilan secara otomatis.
- Transformasi data otomatis.
- Output berupa:
- Persamaan Regresi.
- Statistik Regresi/Kebaikan Suai: R2, R2 terkoreksi, Koefisien Korelasi, AIC, AICc, BIC, RMSE, MAE, MPE, MAPE, dan sMAPE.
- Estimasi Koefisien Regresi: Nilai Koefisien, Standard error, t-statistik, p-value, Upper/Lower, dan VIF.
- Anova: Sekuensial dan Parsial.
- Grafik: Grafik 2D dan 3D untuk Permukaan Respons, serta Optimasi (Maksimum dan Minimum).
Contoh Kasus
Terdapat penelitian mengenai karakteristik beberapa sifat tanah pada dua jenis bahan induk, Andesitik dan Basaltik. Berikut data beberapa sifat tanah pada kedua bahan induk tersebut:
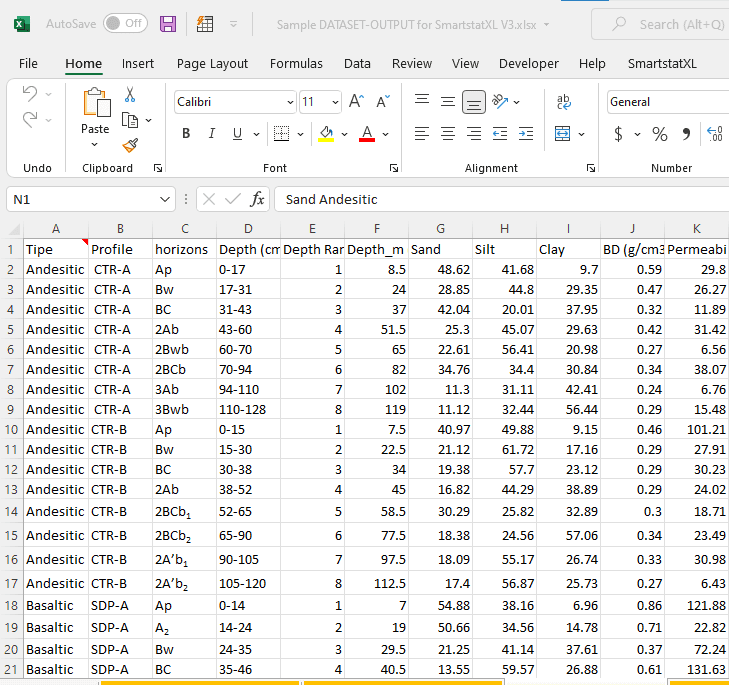
Pada contoh kasus ini, kita bisa membuat pemodelan regresi linier sederhana untuk melihat pengaruh kedalaman tanah (Depth_m) terhadap beberapa sifat tanah tersebut.
Langkah-langkah Analisis Regresi Linier Sederhana
- Aktifkan lembar kerja (Sheet) yang akan dianalisis.
- Tempatkan kursor pada dataset (untuk membuat dataset, lihat cara Persiapan Data).
- Jika sel aktif (Active Cell) tidak berada pada dataset, SmartstatXL akan secara otomatis mencoba menentukan dataset.
- Aktifkan Tab SmartstatXL
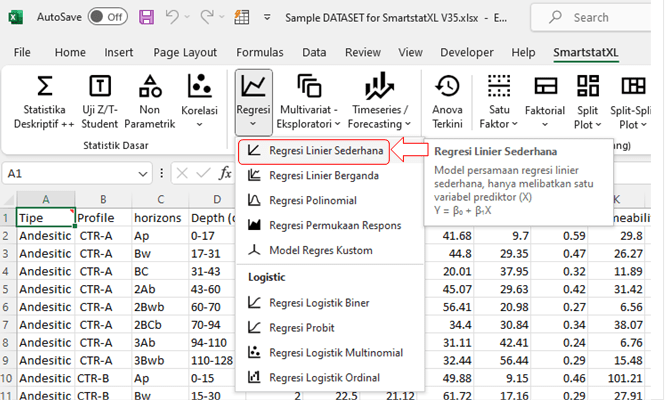
- Klik Menu Regresi > Regresi Linier Sederhana.

- SmartstatXL akan menampilkan kotak dialog untuk memastikan apakah dataset sudah benar atau belum (biasanya dataset sudah otomatis dipilih dengan benar).

- Apabila sudah benar, Klik Tombol Selanjutnya
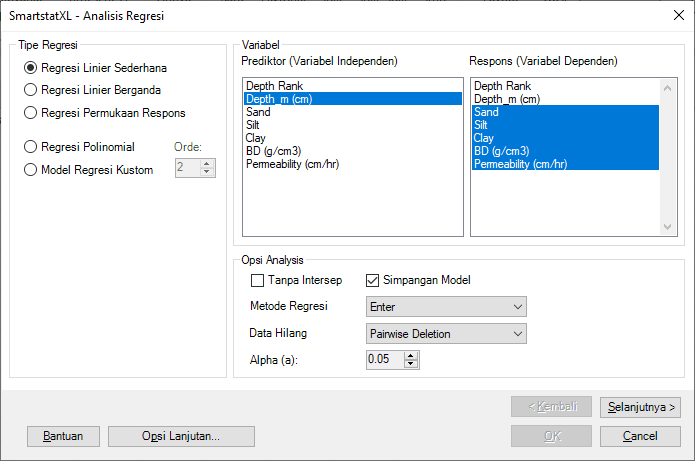
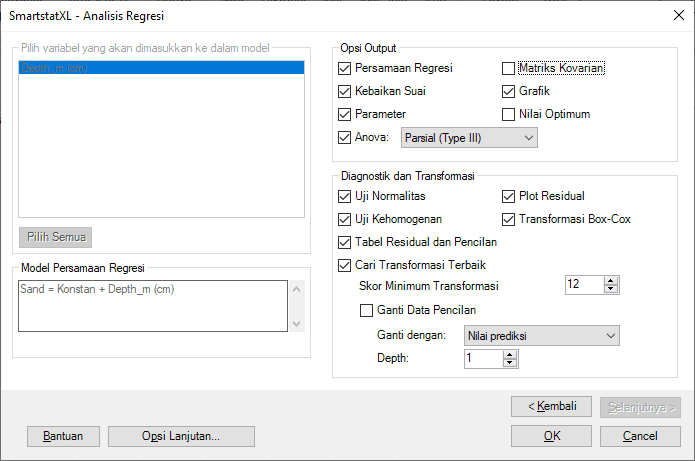
- Selanjutnya akan tampil Kotak Dialog Analisis Regresi. Pilih Variabel Faktor (Independen) dan satu atau lebih Variabel Respons (Dependen). Variabel faktor yang dipilih tergantung pada jenis analisis regresi.
- Model Regresi Linier Sederhana: $Y = {\beta _0} + \;{\beta _1}X$
- Tipe Regresi: "Regresi Linier Sederhana"
- Variabel Respons: "Sand sd. Permeability"
- Variabel Faktor: "Dept_m (cm)"
Selengkapnya, seperti pada tampilan kotak dialog berikut:



- Tekan tombol "Selanjutnya"
- Pilih output regresi seperti pada tampilan berikut:
- Tekan tombol OK untuk membuat outputnya dalam Lembar Output

Hasil Analisis
Informasi Analisis: tipe regresi yang digunakan, metode regresi, respons dan prediktor.
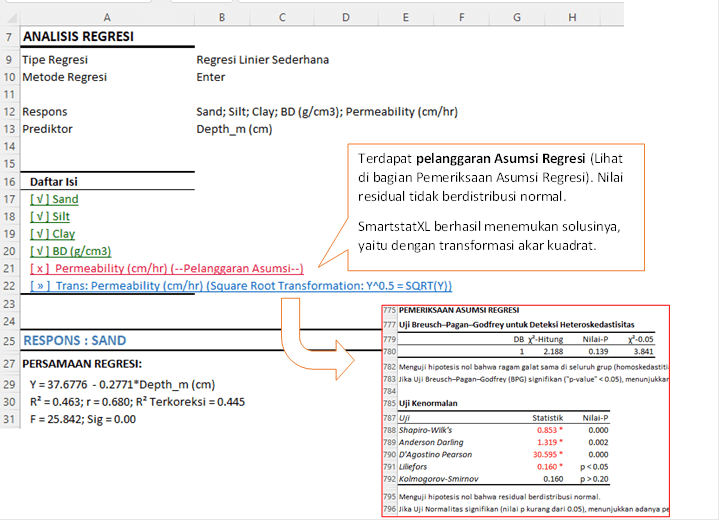
Terdapat pelanggaran Asumsi Regresi untuk parameter Permeability (lihat pada bagian Pemeriksaan Asumsi Regresi). Nilai residual tidak berdistribusi normal. SmartstatXL berhasil menemukan solusinya, yaitu dengan transformasi akar kuadrat.
Interpretasi hasil analisis regresi linier sederhana dapat dijabarkan sebagai berikut:
- Persamaan Regresi: Persamaan regresi Y=37.6776−0.2771×Depth_m menunjukkan hubungan antara kedalaman tanah (Depth_m) dengan kandungan pasir (SAND) di dalam tanah. Koefisien -0.2771 menunjukkan bahwa untuk setiap peningkatan satu unit kedalaman tanah (cm), kandungan pasir akan berkurang sebesar 0.2771 unit.
- Koefisien Determinasi (R2): Nilai R2 sebesar 0.463 menunjukkan bahwa kedalaman tanah dapat menjelaskan sekitar 46.3% variasi dalam kandungan pasir. Sementara itu, sisanya (53.7%) dijelaskan oleh faktor-faktor lain yang tidak dimasukkan dalam model ini.
- Koefisien Korelasi (r): Nilai korelasi r sebesar 0.680 menunjukkan bahwa ada hubungan linear positif yang moderat antara kedalaman tanah dan kandungan pasir.
- R2 Terkoreksi: R2 terkoreksi sebesar 0.445 lebih akurat dalam menggambarkan seberapa baik model memprediksi respons dalam sampel, terutama jika terdapat lebih dari satu prediktor. Dalam kasus ini, R2terkoreksi sedikit lebih rendah daripada R2asli, namun masih menunjukkan bahwa kedalaman tanah memiliki pengaruh yang signifikan terhadap kandungan pasir.
- Uji F: Nilai F sebesar 25.842 dengan tingkat signifikansi (Sig) 0.00 menunjukkan bahwa model regresi secara keseluruhan signifikan dalam memprediksi kandungan pasir berdasarkan kedalaman tanah.
Dalam menulis di artikel ilmiah, kita bisa menuliskannya dengan gaya formal:
Hasil analisis regresi linier sederhana menunjukkan adanya hubungan signifikan antara kedalaman tanah (Depth_m) dengan kandungan pasir (SAND). Persamaan regresi yang diperoleh adalah Y=37.6776−0.2771×Depth_m. Hal ini menandakan bahwa untuk setiap peningkatan satu cm kedalaman tanah, kandungan pasir di dalam tanah akan berkurang sebesar 0.2771 unit.
Koefisien determinasi (R2) sebesar 0.463 mengindikasikan bahwa kedalaman tanah mampu menjelaskan sekitar 46.3% dari variasi kandungan pasir. Sementara koefisien korelasi (r) sebesar 0.680 menunjukkan hubungan linear positif yang moderat antara kedua variabel tersebut.
Uji F memberikan nilai sebesar 25.842 dengan tingkat signifikansi (p-value) sebesar 0.00, menandakan bahwa model regresi yang dibangun memiliki keandalan dalam memprediksi kandungan pasir berdasarkan kedalaman tanah.
Ketepatan Model (Goodness of Fit)
Beberapa nilai statistik kebaikansuai regresi atau lebih dikenal dengan istilah kesesuaian model atau ketepatan model regresi.
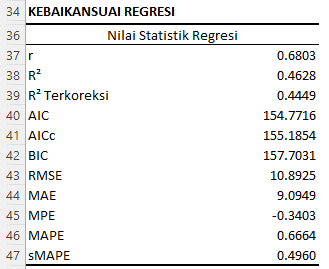
Berikut adalah interpretasi dari hasil analisis kebaikansuai regresi:
- Koefisien Korelasi (r): Dengan nilai korelasi r=0.6803, menunjukkan adanya hubungan linear positif yang moderat antara kedalaman tanah dan kandungan pasir.
- Koefisien Determinasi (R2): Nilai R2=0.4628 mengindikasikan bahwa kedalaman tanah menjelaskan sekitar 46.28% dari variasi kandungan pasir. Sisanya (53.72%) dijelaskan oleh faktor-faktor lain yang tidak dimasukkan dalam model ini.
- R2 Terkoreksi: R2 terkoreksi sebesar 0.4449 lebih akurat dalam menggambarkan seberapa baik model memprediksi respons dalam sampel, terutama jika terdapat lebih dari satu prediktor.
- AIC (Akaike Information Criterion): AIC sebesar 154.7716 adalah ukuran kebaikansuai model regresi. Semakin rendah nilai AIC, semakin baik model tersebut. AIC mempertimbangkan kesesuaian model dan jumlah parameter dalam model.
- AICc (Akaike Information Criterion with a correction for small sample sizes): AICc sebesar 155.1854 adalah koreksi dari AIC untuk sampel yang lebih kecil. Biasanya digunakan saat ukuran sampel kecil relatif terhadap jumlah parameter.
- BIC (Bayesian Information Criterion): BIC sebesar 157.7031 juga merupakan ukuran kebaikansuai model, namun dengan penalti yang lebih besar untuk model dengan lebih banyak parameter. Mirip dengan AIC, semakin rendah nilai BIC, semakin baik model tersebut.
- RMSE (Root Mean Square Error): RMSE sebesar 10.8925 mengukur seberapa besar rata-rata kesalahan antara nilai yang diprediksi oleh model dengan nilai sebenarnya.
- MAE (Mean Absolute Error): MAE sebesar 9.0949 adalah rata-rata dari kesalahan absolut antara nilai yang diprediksi dan nilai sebenarnya.
- MPE (Mean Percentage Error): MPE sebesar -0.3403 mengukur rata-rata kesalahan dalam persentase antara nilai yang diprediksi dan nilai sebenarnya.
- MAPE (Mean Absolute Percentage Error): MAPE sebesar 0.6664 adalah rata-rata kesalahan absolut dalam persentase antara nilai yang diprediksi dan nilai sebenarnya.
- sMAPE (symmetric Mean Absolute Percentage Error): sMAPE sebesar 0.4960 adalah ukuran lain dari kesalahan prediksi dalam persentase yang mempertimbangkan kesalahan overestimasi dan underestimasi dengan cara yang sama.
Dalam konteks ini, penting untuk menilai seberapa baik model berfungsi dan untuk mempertimbangkan ukuran kebaikansuai yang paling relevan dengan tujuan awal. Informasi ini dapat membantu memutuskan apakah model memadai atau apakah penyesuaian lebih lanjut diperlukan.
Koefisien Regresi

Berikut interpretasi dari hasil Analisis regresiLlinier Sederhana:
- Intercept:
- Koefisien: Koefisien untuk intercept adalah 37.678. Ini menunjukkan bahwa ketika kedalaman tanah (Depth_m) adalah 0 cm, kandungan pasir diharapkan sekitar 37.678 unit.
- Simpangan Baku: Simpangan baku dari koefisien intercept adalah 3.686.
- T-Hitung dan Nilai-P: Dengan t-hitung sebesar 10.222 dan p-value sebesar 0.000 (kurang dari 0.01), intercept signifikan pada taraf nyata 1%.
- Interval Kepercayaan 95%: Kita dapat percaya dengan tingkat kepercayaan 95% bahwa nilai sebenarnya dari intercept berada di antara 30.150 dan 45.205.
- Depth_m (cm):
- Koefisien: Koefisien untuk Depth_m adalah -0.277. Hal ini menunjukkan bahwa untuk setiap peningkatan 1 cm pada kedalaman tanah, kandungan pasir diharapkan berkurang sekitar 0.277 unit.
- Simpangan Baku: Simpangan baku dari koefisien Depth_m adalah 0.055.
- T-Hitung dan Nilai-P: Dengan t-hitung sebesar -5.084 dan p-value sebesar 0.000 (kurang dari 0.01), variabel kedalaman tanah signifikan dalam memprediksi kandungan pasir pada taraf nyata 1%.
- Interval Kepercayaan 95%: Kita dapat percaya dengan tingkat kepercayaan 95% bahwa pengurangan kandungan pasir untuk setiap peningkatan 1 cm pada kedalaman tanah berada di antara 0.388-unit dan 0.166 unit.
- VIF (Variance Inflation Factor): VIF untuk Depth_m adalah 1.000, yang menunjukkan tidak adanya masalah multikolinearitas (karena nilai VIF mendekati 1).
Dari hasil analisis di atas, kita dapat menyimpulkan bahwa kedalaman tanah memiliki hubungan yang signifikan dan negatif dengan kandungan pasir. Selain itu, model regresi ini tampaknya tidak memiliki masalah dengan multikolinearitas.
Grafik Regresi dan Analisis Ragam Regresi
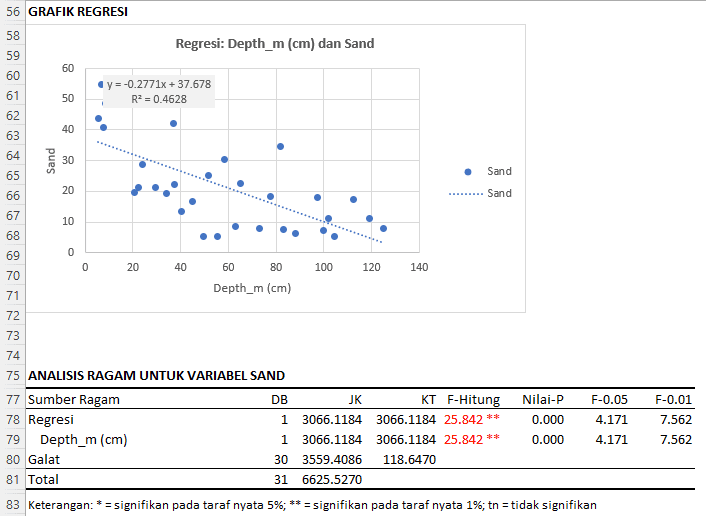
Hasil analisis ragam (ANOVA) mengukur seberapa besar variasi dalam variabel respons (dalam hal ini, SAND) yang dapat dijelaskan oleh variabel independen (kedalaman tanah). Berikut interpretasinya:
- Regresi:
- Derajat Kebebasan (DB): Derajat kebebasan untuk regresi adalah 1, menunjukkan ada satu variabel independen dalam model.
- Jumlah Kuadrat (JK): Jumlah kuadrat untuk regresi adalah 3066.1184, yang mengukur variasi total dalam SAND yang dijelaskan oleh kedalaman tanah.
- Kuadrat Tengah (KT): Kuadrat tengah untuk regresi adalah 3066.1184 (JK dibagi dengan DB). Ini mengukur rata-rata variasi SAND yang dijelaskan oleh setiap unit kedalaman tanah.
- F-Hitung dan Nilai-P: F-hitung untuk regresi adalah 25.842 dengan p-value 0.000. Karena p-value kurang dari 0.01, variabel kedalaman tanah signifikan dalam memprediksi kandungan pasir pada taraf nyata 1%.
- Depth_m (cm): Interpretasi untuk variabel Depth_m mirip dengan interpretasi untuk regresi, karena dalam model ini hanya ada satu variabel independen.
- Galat (Error):
- Derajat Kebebasan (DB): Derajat kebebasan untuk galat adalah 30.
- Jumlah Kuadrat (JK): Jumlah kuadrat untuk galat adalah 3559.4086, yang mengukur variasi total dalam SAND yang tidak dijelaskan oleh kedalaman tanah.
- Kuadrat Tengah (KT): Kuadrat tengah untuk galat adalah 118.6470 (JK dibagi dengan DB). Ini mengukur variabilitas residu atau kesalahan prediksi model.
- Total:
- Derajat Kebebasan (DB): Total derajat kebebasan adalah 31.
- Jumlah Kuadrat (JK): Total variasi dalam SAND adalah 6625.5270.
Kesimpulannya, model regresi yang memasukkan kedalaman tanah sebagai variabel independen signifikan dalam memprediksi kandungan pasir. Dengan F-hitung sebesar 25.842 yang jauh lebih besar dari F kritis pada taraf nyata 5% (4.171) dan 1% (7.562), kita dapat menolak hipotesis nol yang menyatakan bahwa variabel independen tidak memiliki pengaruh terhadap variabel respons.
Pemeriksaan Asumsi Regresi

Dalam analisis regresi, penting untuk memeriksa asumsi-asumsi yang mendasarinya agar hasil yang diperoleh valid dan dapat diandalkan, terutama uji normalitas dan uji heteroskedastisitas. Berikut interpretasi dari hasil Pemeriksaan Asumsi Regresi.
Uji Homoskedastisitas
Uji Breusch–Pagan–Godfrey digunakan untuk mendeteksi heteroskedastisitas dalam model regresi. Hipotesis untuk uji ini adalah sebagai berikut:
- Hipotesis Nol (H0):
Tidak ada heteroskedastisitas dalam model, yaitu variabilitas dari kesalahan regresi (residual) konstan di seluruh rentang nilai variabel independen. - Hipotesis Alternatif (H1):
Ada heteroskedastisitas dalam model, yaitu variabilitas dari kesalahan regresi (residual) tidak konstan di seluruh rentang nilai variabel independen.
Dengan kata lain:
- Jika kita menolak H0 (misalnya, jika nilai p kurang dari 0.05), ini menunjukkan adanya bukti yang mendukung heteroskedastisitas dalam model.
- Jika kita gagal menolakH0 (misalnya, jika nilai p lebih besar dari 0.05), ini menunjukkan tidak ada bukti yang mendukung heteroskedastisitas dalam model, sehingga asumsi homoskedastisitas dianggap terpenuhi.
Dari hasil perhitungan didapatkan:
- Nilai χ²-Hitung adalah 3.260.
- Nilai-P yang diperoleh dari uji BPG adalah 0.071.
Interpretasi:
Karena nilai p (0.071) lebih besar dari 0.05, kita gagal menolak hipotesis nol yang menyatakan bahwa ragam (variansi) residual sama di semua tingkat kedalaman tanah (homoskedastisitas). Dengan kata lain, tidak ada bukti yang cukup untuk mengatakan bahwa terdapat heteroskedastisitas dalam data.
Uji Normalitas
Uji-tes kenormalan menguji apakah residual (kesalahan) dari model regresi berdistribusi normal, yang merupakan salah satu asumsi kunci dalam regresi linier.Berikut hipotesis untuk Uji Normalitas:
- Hipotesis Nol (H0): Residual berdistribusi normal.
- Hipotesis Alternatif (H1): Residual tidak berdistribusi normal.
Dengan kata lain:
- Jika kita menolak H0 (misalnya, jika nilai p kurang dari 0.05), ini menunjukkan adanya bukti yang mendukung klaim bahwa residual tidak berdistribusi normal, sehingga melanggar asumsi normalitas.
- Jika kita gagal menolak H0 (misalnya, jika nilai p lebih besar dari 0.05), ini menunjukkan tidak ada bukti yang mendukung klaim bahwa residual tidak berdistribusi normal, sehingga asumsi normalitas dianggap terpenuhi.
Dari hasil perhitungan didapatkan:
- Shapiro-Wilk's: Dengan statistik sebesar 0.965 dan nilai p sebesar 0.371, data tidak menunjukkan pelanggaran terhadap asumsi normalitas.
- Anderson Darling: Dengan statistik sebesar 0.359 dan nilai p sebesar 0.452, data tidak menunjukkan pelanggaran terhadap asumsi normalitas.
- D'Agostino Pearson: Dengan statistik sebesar 1.597 dan nilai p sebesar 0.450, data tidak menunjukkan pelanggaran terhadap asumsi normalitas.
- Liliefors & Kolmogorov-Smirnov: Kedua uji ini menunjukkan nilai statistik 0.118 dan nilai p lebih besar dari 0.20, yang menegaskan bahwa data tidak menunjukkan pelanggaran terhadap asumsi normalitas.
Interpretasi:
Karena semua nilai p dari uji-tes kenormalan di atas lebih besar dari 0.05, kita gagal menolak hipotesis nol yang menyatakan bahwa residual berdistribusi normal. Ini berarti asumsi normalitas terpenuhi untuk data tersebut.
Kesimpulannya, berdasarkan hasil Pemeriksaan Asumsi Regresi, model regresi tampak memenuhi asumsi homoskedastisitas dan normalitas, yang berarti model regresi cukup valid dan dapat diandalkan untuk analisis lebih lanjut.
Plot Residual
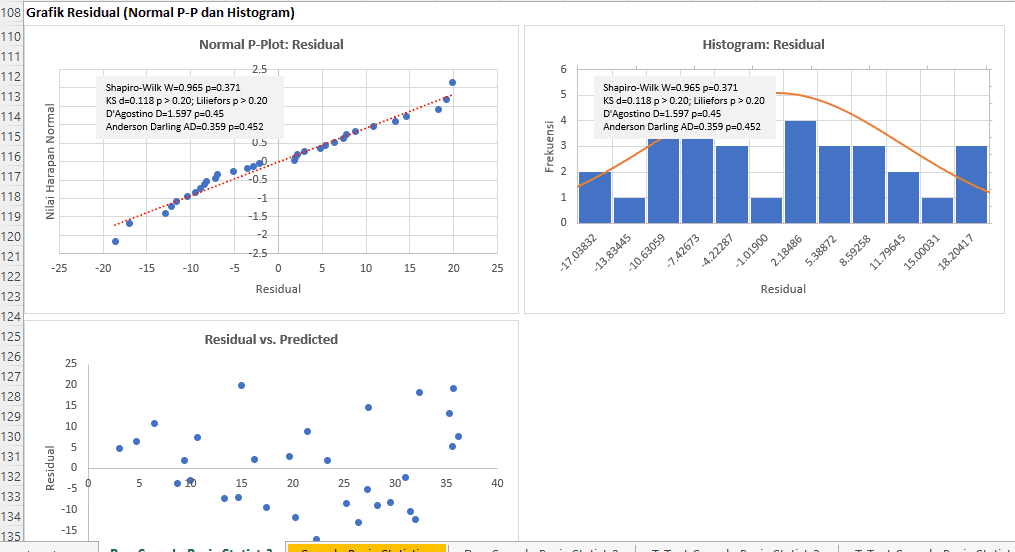
Selain uji formal, pemeriksaan asumsi normalitas bisa juga dilakukan secara visual dengan menggunakan plot residual yang disertakan. Pemeriksaan bisa dilakukan dengan menggunakan Normal Probability Plot (Normal P-Plot), Histogram, Plot Residual vs. Predicted.
- Normal P-Plot untuk Residual:
- Normal Probability Plot antara nilai residual dengan nilai prediksi atau observasi. Idealnya, titik-titik pada plot ini harus mengikuti garis diagonal lurus. Jika titik-titik menyimpang dari garis diagonal, ini mungkin menunjukkan penyimpangan dari normalitas.
- Fakta bahwa titik-titik hampir mengikuti garis diagonal lurus menunjukkan bahwa residual memiliki distribusi yang mendekati normal di sebagian besar rentang nilai. Ini adalah tanda yang baik dan menunjukkan bahwa asumsi normalitas residual hampir terpenuhi.Namun, keberadaan titik yang menyimpang dari garis diagonal di kedua ujung menunjukkan adanya penyimpangan dari normalitas di ekor distribusi.
- Meskipun ada beberapa penyimpangan dari normalitas, tergantung pada konteks dan tujuan analisis, penyimpangan ini mungkin tidak signifikan. Namun, jika analisis kita sangat sensitif terhadap asumsi normalitas, kita mungkin perlu mempertimbangkan teknik transformasi atau metode lain untuk memperbaiki penyimpangan ini.
- Histogram untuk Residual:
- Histogram harus menunjukkan distribusi yang mendekati bentuk lonceng (distribusi normal). Penyimpangan dari bentuk ini (misalnya, distribusi yang miring atau berbuntut panjang) dapat menunjukkan pelanggaran asumsi normalitas.
- Residual vs Predicted:
- Untuk memeriksa homoskedastisitas, titik-titik pada plot ini harus tersebar secara acak di sekitar garis horizontal di 0 tanpa pola tertentu. Jika melihat pola khusus, seperti bentuk corong atau pola berbentuk kurva, ini dapat menunjukkan heteroskedastisitas atau pelanggaran lain dari asumsi regresi.
Mengingat bahwa semua uji formal menunjukkan bahwa residual berdistribusi normal (karena semua nilai p lebih besar dari 0.05), penyimpangan kecil yang pada Normal P-Plot kemungkinan bukan masalah besar.
Dalam praktiknya, analisis regresi seringkali cukup toleran terhadap pelanggaran kecil dari asumsi normalitas, terutama jika ukuran sampel cukup besar. Oleh karena itu, meskipun ada beberapa titik yang menyimpang dari garis diagonal pada Normal P-Plot, jika uji formal menunjukkan normalitas dan kita tidak melihat pelanggaran asumsi lain yang signifikan, model regresi mungkin dianggap cukup valid untuk keperluan analisis.
Transformasi Box-Cox dan Analisis Residual
Transformasi Box-Cox sering direkomendasikan untuk memperbaiki asumsi-asumsi yang dilanggar dalam analisis regresi, terutama normalitas dan homoskedastisitas. Namun, jika hasil analisis sudah menunjukkan bahwa semua asumsi regresi terpenuhi (seperti pada contoh kasus ini), maka mungkin tidak perlu melakukan transformasi.
Ada beberapa poin yang harus dipertimbangkan:
- Tidak Selalu Perlu: Meskipun Box-Cox mungkin menyarankan transformasi, itu tidak berarti kita harus melakukannya. Saran ini lebih relevan ketika ada pelanggaran nyata terhadap asumsi-asumsi regresi.
- Interpretasi: Transformasi data dapat mempengaruhi interpretasi koefisien regresi. Misalnya, dengan transformasi logaritmik, koefisien menjadi elastisitas, yang mengukur persentase perubahan variabel respons untuk setiap persentase perubahan variabel prediktor.
- Pengujian Lebih Lanjut: Jika memutuskan untuk mengikuti saran Box-Cox dan mentransformasi data, kita harus menjalankan model regresi lagi dan memeriksa semua asumsi regresi untuk dataset yang telah ditransformasi.
- Konteks: Selalu pertimbangkan konteks dan tujuan penelitian. Jika asumsi sudah terpenuhi, memperkenalkan transformasi mungkin tidak perlu dan hanya akan mempersulit interpretasi.
Kesimpulannya, jika kita sudah memeriksa dan memastikan bahwa asumsi-asumsi regresi terpenuhi, mungkin tidak perlu melakukan transformasi Box-Cox. Namun, jika ingin melihat bagaimana transformasi mempengaruhi model, kita dapat mencobanya dan membandingkan hasilnya dengan model yang asli.
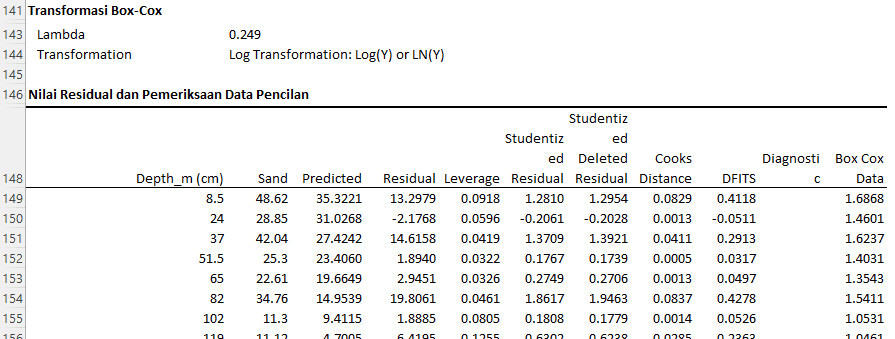
Berdasarkan hasil diagnostik tersebut, berikut contoh interpretasi untuk 3 baris pertama:
- Residual: Residual adalah perbedaan antara nilai yang diobservasi (SAND) dan nilai yang diprediksi oleh model. Residual yang besar dapat menunjukkan bahwa model kita tidak memprediksi observasi tertentu dengan baik.
- Untuk observasi pertama (kedalaman 8.5 cm), residual positif sebesar 13.2979 menunjukkan bahwa model memprediksi nilai SAND yang lebih rendah dari yang sebenarnya diamati.
- Untuk observasi kedua (kedalaman 24 cm), residual negatif sebesar -2.1768 menunjukkan bahwa model memprediksi nilai SAND yang lebih tinggi dari yang sebenarnya diamati.
- Untuk observasi ketiga (kedalaman 37 cm), residual positif sebesar 14.6158 menunjukkan kembali bahwa model memprediksi nilai SAND yang lebih rendah dari yang sebenarnya diamati.
- Leverage: Nilai leverage mengukur sejauh mana nilai prediktor (X) adalah ekstrem atau tidak biasa relatif terhadap nilai prediktor lainnya. Leverage yang tinggi dapat menunjukkan nilai X yang ekstrem.
- Observasi pertama memiliki leverage 0.0918, yang tampaknya relatif tinggi dibandingkan dengan observasi lainnya. Ini menunjukkan bahwa kedalaman 8.5 cm mungkin merupakan nilai yang tidak biasa atau ekstrem dalam data.
- Studentized Residual: Ini adalah versi residual yang telah distandarisasi, yang memungkinkan kita untuk mengidentifikasi outlier dalam respons (Y). Nilai absolut dari residual studentized yang besar (seringkali > 2 atau 3) dapat menunjukkan outlier.
- Observasi pertama dan ketiga memiliki residual studentized yang lebih besar dari 1, yang menunjukkan potensi outlier dalam respons.
- Cook's Distance: Mengukur pengaruh dari setiap observasi terhadap semua estimasi regresi. Nilai Cook's Distance yang besar dapat menunjukkan observasi yang berpengaruh tinggi.
- Observasi pertama memiliki Cook's Distance sebesar 0.0829, yang mungkin menunjukkan bahwa observasi ini memiliki pengaruh yang relatif besar terhadap model.
- DFITS: Mirip dengan Cook's Distance, DFITS adalah ukuran pengaruh dari setiap observasi. Nilai DFITS yang besar (seringkali > 2) dapat menunjukkan observasi yang berpengaruh tinggi.
- Observasi pertama memiliki DFITS sebesar 0.4118, yang menunjukkan potensi pengaruh pada model.
Kesimpulan
Berdasarkan hasil analisis yang telah dilakukan:
- Model Regresi: Persamaan regresi yang diperoleh menunjukkan hubungan negatif antara kedalaman tanah (Depth_m) dan kandungan pasir (SAND). Ini berarti dengan meningkatnya kedalaman tanah, kandungan pasir diharapkan berkurang.
- Uji Goodness-of-Fit: Koefisien determinasi R2 menunjukkan bahwa sekitar 46,28% variasi dalam kandungan pasir dapat dijelaskan oleh model. Namun, R2 Terkoreksi menunjukkan bahwa setelah mengakomodasi derajat kebebasan, sekitar 44,49% variasi dijelaskan.
- Uji Asumsi: Tidak ditemukan pelanggaran signifikan terhadap asumsi regresi. Uji Breusch–Pagan–Godfrey menunjukkan bahwa model memenuhi asumsi homoskedastisitas. Selanjutnya, berbagai Uji Normalitas menegaskan bahwa residual dari model berdistribusi normal.
- Diagnostik Data: Meskipun model secara keseluruhan tampak baik, ada beberapa observasi yang mungkin berperan sebagai outlier atau memiliki pengaruh tinggi pada model, seperti yang ditunjukkan oleh analisis residual dan nilai leverage.
Penulisan Hasil dan Pembahasan dalam Karya Ilmiah
Dalam penelitian ini, kami mengevaluasi hubungan antara kedalaman tanah dan kandungan pasir menggunakan regresi linier sederhana. Analisis menunjukkan hubungan negatif antara kedalaman tanah dan kandungan pasir. Seiring dengan peningkatan kedalaman tanah, kandungan pasir diharapkan berkurang. Model regresi yang dikembangkan berhasil menjelaskan sekitar 44,49% variasi dalam kandungan pasir.
Sebagai langkah validasi model, kami memeriksa beberapa asumsi kunci yang mendasari analisis regresi. Pertama, kami memastikan bahwa variabilitas dari kesalahan regresi (residual) konstan di seluruh rentang nilai variabel independen, sebuah konsep yang dikenal sebagai homoskedastisitas. Melalui Uji Breusch–Pagan–Godfrey, asumsi ini terkonfirmasi. Selanjutnya, kami memeriksa distribusi dari residual, yang idealnya harus berdistribusi normal. Melalui serangkaian Uji Normalitas, termasuk Shapiro-Wilk's, Anderson Darling, D'Agostino Pearson, Liliefors, dan Kolmogorov-Smirnov, kami dapat memastikan bahwa residual model berdistribusi normal.
Namun, meskipun model memenuhi asumsi-asumsi dasar, analisis diagnostik tambahan menunjukkan adanya beberapa observasi yang mungkin berperan sebagai outlier atau memiliki pengaruh tinggi. Ini menggarisbawahi pentingnya selalu melakukan pemeriksaan menyeluruh terhadap model regresi, bahkan ketika model pada awalnya tampak memenuhi semua kriteria.
Dengan demikian, temuan ini memberikan wawasan yang berharga tentang hubungan antara kedalaman tanah dan kandungan pasir. Namun, perlu diingat bahwa interpretasi harus dilakukan dengan hati-hati, terutama jika akan diterapkan dalam konteks yang berbeda atau digunakan untuk tujuan prediktif.