SmartstatXL menawarkan berbagai jenis analisis regresi untuk memodelkan hubungan antara variabel bebas (independen) dan variabel terikat (dependen). Salah satu jenis analisis yang dapat dilakukan dengan SmartstatXL adalah Regresi Logistik Multinomial.
Regresi Logistik Multinomial dirancang khusus untuk situasi di mana variabel dependen bersifat nominal dengan lebih dari dua level atau kategori. Meskipun memiliki kesamaan dengan regresi linier berganda dalam hal analisis prediktif, regresi multinomial memfokuskan pada variabel dependen nominal. Tujuan utamanya adalah untuk menjelaskan hubungan antara variabel dependen dengan satu atau lebih variabel independen.
Sebagai contoh, jika ingin memprediksi preferensi makanan seseorang berdasarkan beberapa variabel independen, outcome yang mungkin meliputi: Vegetarian, Non-Vegetarian, dan Vegan.
Fitur unggulan analisis regresi multinomial (nominal) dengan aplikasi SmartstatXL:
- Diagnostik Regresi:
- Informasi data pencilan.
- Kemampuan untuk mengkodekan outcome dalam bentuk angka (0, 1) atau teks (Ya, Tidak; Y, T; Sukses, Gagal, dan lain-lain).
- Penyesuaian respons event untuk outcome.
- Output berupa:
- Persamaan Regresi.
- Statistik Regresi/Kebaikan Suai: R², Cox-Snell R², Nagelkerke R², AIC, AICc, BIC, Log Likelihood.
- Estimasi Koefisien Regresi: Nilai Koefisien, Standard error, Wald Stat, p-value, Upper/Lower, VIF.
- Tabel Analisis Devians.
- Confusion Matrix (Tabel Klasifikasi dan Metrik).
Contoh Kasus
Iris Dataset: Awalnya diterbitkan di UCI Machine Learning Repository.
Sejak tahun 1936, dataset Iris ini sering digunakan untuk menguji algoritma dan visualisasi pembelajaran mesin. Kumpulan data Iris adalah dataset klasifikasi yang berisi tiga kelas dengan masing-masing 50 instance, di mana setiap kelas mengacu pada jenis tanaman iris. Ketiga kelas dalam kumpulan data Iris adalah: Setosa, Versicolor, Virginica. Setiap baris dari tabel mewakili bunga iris, termasuk spesies dan dimensi bagian botaninya, panjang sepal, lebar sepal, panjang petal, dan lebar petal (dalam sentimeter).

Author: R.A. Fisher (1936)
Source: UCI Machine Learning Repository
Langkah-langkah Analisis Regresi Multinomial
- Aktifkan lembar kerja (Sheet) yang akan dianalisis.
- Tempatkan kursor pada dataset (untuk membuat dataset, lihat cara Persiapan Data).
- Jika sel aktif (Active Cell) tidak berada pada dataset, SmartstatXL akan secara otomatis mencoba menentukan dataset.
- Aktifkan Tab SmartstatXL
- Klik Menu Regresi > Regresi Multinomial.

- SmartstatXL akan menampilkan kotak dialog untuk memastikan apakah dataset sudah benar atau belum (biasanya dataset sudah otomatis dipilih dengan benar).

- Apabila sudah benar, Klik Tombol Selanjutnya
- Selanjutnya akan tampil Kotak Dialog Analisis Regresi:Pilih Variabel Prediktor (Independen) dan satu atau lebih Variabel Respons (Dependen).

- Tekan tombol "Selanjutnya"
- Pilih output regresi seperti pada tampilan berikut (Misalkan Referensi=Virginica):
Kategori yang dijadikan sebagai Referensi, bisa kategori pertama (SETOSA) atau kategori terakhir (VIRGINICA). Kategori referensi juga bisa langsung dipilih dari level outcome. Pada contoh ini, misalnya Respons Event adalah VIRGINICA. - Tekan tombol OK untuk membuat outputnya dalam Lembar Output



Hasil Analisis
Informasi Analisis: tipe regresi yang digunakan, metode regresi, respons dan prediktor

Pada analisis Regresi Multinomial ini: "Species" sebagai variabel respons dan empat prediktor yaitu "Sepal length", "Sepal width", "Petal length", dan "Petal width".
Persamaan Regresi Multinomial

Berikut persamaan regresi multinomial:
- Setosa:
- Y=33.146+11.8539×Sepal length+13.3007×Sepal width−26.916×Petal length−37.9963×Petal width
- Untuk setiap kenaikan satu unit pada panjang sepal, nilai Y (kemungkinan spesies menjadi Setosa) meningkat sebesar 11.8539 unit, dengan asumsi variabel lainnya tetap.
- Untuk setiap kenaikan satu unit pada lebar sepal, nilai Y meningkat sebesar 13.3007 unit.
- Sebaliknya, untuk setiap kenaikan satu unit pada panjang petal, nilai Y berkurang sebesar 26.916 unit.
- Dan, untuk setiap kenaikan satu unit pada lebar petal, nilai Y berkurang sebesar 37.9963 unit.
- Versicolor:
- Y=42.6378+2.4652×Sepal length+6.6809×Sepal width−9.4294×Petal length−18.2861×Petal width
- Untuk setiap kenaikan satu unit pada panjang sepal, nilai Y (kemungkinan spesies menjadi Versicolor) meningkat sebesar 2.4652 unit, dengan asumsi variabel lainnya tetap.
- Untuk setiap kenaikan satu unit pada lebar sepal, nilai Y meningkat sebesar 6.6809 unit.
- Sebaliknya, untuk setiap kenaikan satu unit pada panjang petal, nilai Y berkurang sebesar 9.4294 unit.
- Dan, untuk setiap kenaikan satu unit pada lebar petal, nilai Y berkurang sebesar 18.2861 unit.
- Metrik Evaluasi Model:
- R2 adalah 0.964, yang berarti bahwa 96.4% variasi dalam spesies dapat dijelaskan oleh keempat prediktor ini. Ini menunjukkan bahwa model regresi kita memiliki kesesuaian yang sangat baik dengan data.
- Nilai Chi-Squared adalah 317.685 dengan tingkat signifikansi (Sig) sebesar 0.00. Ini menunjukkan bahwa model regresi kita adalah signifikan dalam memprediksi spesies berdasarkan keempat prediktor yang diberikan.
Pada regresi multinomial, kita memprediksi probabilitas logaritmik (log-odds) dari suatu kategori terhadap kategori referensi. Dalam kasus ini, tampaknya ada tiga kategori (Setosa, Versicolor, dan Virginica), tetapi hanya ada dua persamaan regresi yang diberikan. Ini karena kategori ketiga (kemungkinan besar Virginica) dianggap sebagai kategori referensi, dan log-odds-nya adalah nol (dalam skala logit).
Untuk memprediksi outcome dari suatu observasi, lakukan langkah-langkah berikut:
- Hitung log-odds untuk Setosa dan Versicolor menggunakan persamaan regresi yang diberikan.
- Konversi log-odds ini ke probabilitas menggunakan rumus:
- $Probabilitas\; = \;\frac{{{e^{log - odds}}}}{{1 + {e^{log - odds}}}}$
- Probabilitas untuk Virginica dapat dihitung sebagai:
- ${\rm{Probabilitas\;Virginica}} = 1 - \left( {{\rm{Probabilitas\;Setosa}} + {\rm{Probabilitas\;Versicolor}}} \right)$
- Kategori dengan probabilitas tertinggi dianggap sebagai prediksi model untuk observasi tersebut.
Contoh Perhitungan:
Misalkan kita memiliki observasi dengan karakteristik berikut:
- Sepal length = 5 cm
- Sepal width = 3.5 cm
- Petal length = 1.5 cm
- Petal width = 0.5 cm
Langkah 1: Hitung log-odds untuk Setosa dan Versicolor
- Log-odds Setosa=33.146+11.8539(5)+13.3007(3.5)−26.916(1.5)−37.9963(0.5)= 79.5960
- Log-odds Versicolor=42.6378+2.4652(5)+6.6809(3.5)−9.4294(1.5)−18.2861(0.5) = 55.0599
Langkah 2: Konversi log-odds ke probabilitas
$Probabilitas\;Setosa\; = \;\frac{{{e^{{\rm{Log}} - {\rm{odds\;Setosa}}}}}}{{1 + {e^{{\rm{Log}} - {\rm{odds\;Setosa}}}} + {e^{{\rm{Log}} - {\rm{odds\;Versicolor}}}}}}$
$ = \;\frac{{{{10}^{79.5960}}}}{{1 + {{10}^{79.5960}} + {{10}^{55.0599}}}} \approx 1$
$ = \;1$
$Probabilitas\;Versicolor\; = \;\frac{{{e^{{\rm{Log}} - {\rm{odds\;Virginica}}}}}}{{1 + {e^{{\rm{Log}} - {\rm{odds\;Setosa}}}} + {e^{{\rm{Log}} - {\rm{odds\;Versicolor}}}}}}$
$ = \;\frac{{{{10}^{55.0599}}}}{{1 + {{10}^{79.5960}} + {{10}^{55.0599}}}} \approx 1$
$ = \;0$
Langkah 3: Hitung probabilitas untuk Virginica
$Probabilitas\;Virginica\; = \;1 - \left( {Probabilitas\;Setosa + Probabilitas\;Versicolor} \right)$
$ = \;1 - \left( {1 + 0} \right)$
$ = \;0$
Langkah 4: Tentukan kategori dengan probabilitas tertinggi
Berdasarkan perhitungan:
- Probabilitas untuk Setosa adalah ≈100%
- Probabilitas untuk Versicolor adalah ≈0%
- Probabilitas untuk Virginica juga ≈0%
Berdasarkan probabilitas yang diperoleh, model kita akan memprediksi bahwa observasi ini termasuk dalam kategori Setosa karena memiliki probabilitas tertinggi.
Dalam contoh ini, model kita sangat yakin bahwa bunga yang diberikan adalah Setosa, dengan probabilitas mendekati 100%. Probabilitas untuk kategori lainnya sangat rendah, mendekati nol.
Ketepatan Model (Goodness of Fit)

Berikut interpretasi untuk hasil analisis kebaikansuai regresi atau ketepatan model regresi:
- R² (Koefisien Determinasi) = 0.9639:
- Koefisien determinasi (R2) mengukur seberapa baik variasi dalam variabel respons dijelaskan oleh model regresi. Dengan nilai R2 sebesar 0.9639, ini berarti 96.39% dari variasi dalam spesies dapat dijelaskan oleh model regresi kita. Ini adalah indikasi dari tingkat kecocokan yang sangat baik antara model dan data.
- Cox-Snell R² = 0.8797:
- Ini adalah ukuran kebaikansuai model yang disesuaikan untuk regresi logistik. Nilai ini mengukur seberapa baik model kita memprediksi hasil yang diamati. Sebuah nilai yang mendekati 1 menunjukkan kecocokan yang baik.
- Nagelkerke R² = 0.9897:
- Mirip dengan Cox-Snell R², tetapi ini adalah versi yang dinormalisasi sehingga memiliki rentang yang lebih familiar dari 0 hingga 1. Nilai ini juga mengindikasikan kecocokan yang sangat baik antara model dan data.
- AIC (Akaike Information Criterion) = 31.8985:
- AIC mengukur kualitas relatif dari model statistik. Model dengan AIC yang lebih rendah dianggap lebih baik. Ini penting ketika membandingkan beberapa model; model dengan AIC terendah lebih diutamakan.
- AICc (Akaike Information Criterion dengan koreksi) = 32.3152:
- Versi AIC yang telah dikoreksi untuk ukuran sampel. Dalam kasus di mana ukuran sampel kecil dan/atau jumlah prediktor tinggi, AICc lebih disukai daripada AIC.
- BIC (Bayesian Information Criterion) = 62.0049:
- Seperti AIC, BIC juga digunakan untuk membandingkan kualitas model. Namun, BIC memberikan hukuman yang lebih besar untuk model dengan lebih banyak parameter. Model dengan BIC yang lebih rendah lebih diutamakan.
- Log Likelihood = -5.9493:
- Ini adalah ukuran dari kemungkinan bahwa model kita adalah model yang "benar". Nilai yang lebih tinggi menunjukkan model yang lebih baik. Nilai negatif adalah normal dan dapat diartikan sebagai seberapa jauh nilai ini dari nol; semakin dekat dengan nol, semakin baik modelnya.
Interpretasi di atas memberikan gambaran tentang seberapa baik model regresi kita cocok dengan data yang diberikan dan seberapa baik model tersebut dalam memprediksi respons berdasarkan prediktor yang ada.
Estimasi koefisien regresi
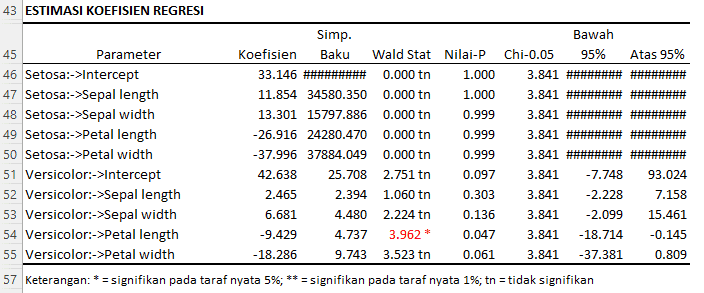
Berikut interpretasi untuk hasil estimasi koefisien regresi:
Untuk Spesies Setosa:
- Intercept (Konstanta) = 33.146:
- Ketika semua variabel prediktor bernilai nol, nilai rata-rata dari respons (dalam konteks log-odds) untuk Setosa adalah 33.146. Namun, simpangan bakunya yang sangat tinggi dan nilai Wald Stat yang mendekati nol menunjukkan bahwa estimasi ini tidak stabil dan mungkin tidak signifikan.
- Sepal length:
- Untuk setiap kenaikan satu unit pada panjang sepal, log-odds dari Setosa meningkat sebesar 11.854 unit, dengan asumsi variabel lainnya tetap. Namun, berdasarkan Wald Stat dan Nilai-P, koefisien ini tidak signifikan pada taraf nyata 5%.
- Sepal width:
- Untuk setiap kenaikan satu unit pada lebar sepal, log-odds dari Setosa meningkat sebesar 13.301 unit. Koefisien ini juga tidak signifikan pada taraf nyata 5%.
- Petal length:
- Untuk setiap kenaikan satu unit pada panjang petal, log-odds dari Setosa berkurang sebesar 26.916 unit. Koefisien ini juga tidak signifikan pada taraf nyata 5%.
- Petal width:
- Untuk setiap kenaikan satu unit pada lebar petal, log-odds dari Setosa berkurang sebesar 37.996 unit. Koefisien ini juga tidak signifikan pada taraf nyata 5%.
Untuk Spesies Versicolor:
- Intercept (Konstanta) = 42.638:
- Ketika semua variabel prediktor bernilai nol, nilai rata-rata dari respons (dalam konteks log-odds) untuk Versicolor adalah 42.638. Koefisien ini mendekati signifikansi pada taraf nyata 10%.
- Sepal length:
- Untuk setiap kenaikan satu unit pada panjang sepal, log-odds dari Versicolor meningkat sebesar 2.465 unit. Koefisien ini tidak signifikan pada taraf nyata 5%.
- Sepal width:
- Untuk setiap kenaikan satu unit pada lebar sepal, log-odds dari Versicolor meningkat sebesar 6.681 unit. Koefisien ini juga tidak signifikan pada taraf nyata 5%.
- Petal length:
- Untuk setiap kenaikan satu unit pada panjang petal, log-odds dari Versicolor berkurang sebesar 9.429 unit. Koefisien ini signifikan pada taraf nyata 5% berdasarkan Wald Stat dan Nilai-P.
- Petal width:
- Untuk setiap kenaikan satu unit pada lebar petal, log-odds dari Versicolor berkurang sebesar 18.286 unit. Koefisien ini mendekati signifikansi pada taraf nyata 10%.
Keterangan:
- Koefisien yang ditandai dengan simbol (*) adalah signifikan pada taraf nyata 5%. Ini berarti ada bukti kuat bahwa koefisien tersebut berbeda dari nol dan memiliki pengaruh nyata pada respons.
- Koefisien yang tidak memiliki tanda (tn) menunjukkan bahwa koefisien tersebut tidak signifikan pada taraf nyata 5% atau 1%. Ini berarti tidak ada bukti kuat bahwa koefisien tersebut berbeda dari nol.
Interpretasi di atas memberikan gambaran tentang pengaruh masing-masing prediktor terhadap respons dalam konteks log-odds untuk masing-masing spesies.
Analisis deviance/ragam

Analisis deviance digunakan untuk mengevaluasi seberapa baik model kita memprediksi data yang diamati. Deviance adalah ukuran ketidakcocokan antara model yang diusulkan dengan model yang sempurna (yang akan memprediksi data dengan sempurna).
- Regresi:
- DB (Derajat Bebas) = 9: Ini menunjukkan jumlah parameter yang diestimasi dalam model regresi, tidak termasuk konstanta.
- Deviance = 317.685: Ini adalah deviance yang dihasilkan dari model regresi kita. Deviance ini menunjukkan seberapa jauh model kita dari model yang sempurna.
- Nilai-P = 0.000: Nilai p ini menunjukkan bahwa model regresi kita signifikan pada taraf nyata 1%. Dengan kata lain, ada bukti kuat bahwa model kita memprediksi respons dengan lebih baik dibandingkan dengan model yang hanya memiliki konstanta (tanpa prediktor).
- Chi.05 = 16.919 dan Chi.01 = 21.666: Ini adalah nilai kritis dari distribusi chi-kuadrat pada taraf signifikansi 5% dan 1% untuk 9 derajat kebebasan. Karena deviance model kita (317.685) jauh lebih besar dari kedua nilai kritis ini, hal ini mendukung kesimpulan bahwa model kita signifikan.
- Galat:
- DB (Derajat Bebas) = 140: Ini menunjukkan jumlah pengamatan dikurangi dengan jumlah parameter yang diestimasi (termasuk konstanta).
- Deviance = 11.8985: Ini adalah deviance yang tersisa setelah mempertimbangkan efek dari prediktor dalam model. Ini menunjukkan seberapa jauh model dengan hanya konstanta (tanpa prediktor) dari model yang sempurna.
- Total:
- DB (Derajat Bebas) = 149: Total derajat kebebasan.
- Deviance = 329.5837: Total deviance dari data.
Keterangan:
- Deviance yang signifikan (∗∗) pada taraf nyata 1% menunjukkan bahwa model kita memiliki kecocokan yang baik dengan data dan memprediksi respons dengan lebih baik dibandingkan dengan model yang hanya memiliki konstanta.
Interpretasi di atas memberikan gambaran tentang seberapa baik model regresi kita dalam memprediksi variabel respons (Species) berdasarkan prediktor yang ada.
Tabel Klasifikasi (Confussion Matrix)
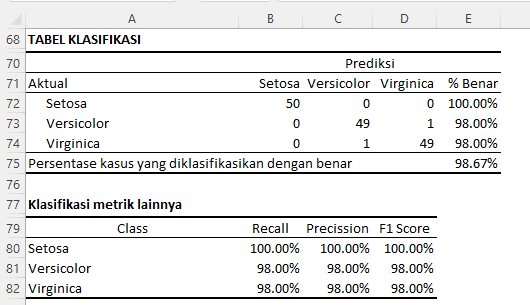
Berikut interpretasi untuk hasil analisis tabel klasifikasi dan metrik klasifikasi lainnya:
Tabel Klasifikasi
Tabel klasifikasi, juga dikenal sebagai matriks konfusi, menunjukkan bagaimana model kita mengklasifikasikan setiap kasus dalam data pengujian atau pelatihan.
- Setosa:
- Dari 50 bunga yang sebenarnya adalah Setosa, semua 50 bunga tersebut diklasifikasikan dengan benar sebagai Setosa oleh model kita. Ini memberikan tingkat akurasi klasifikasi sebesar 100.00% untuk spesies Setosa.
- Versicolor:
- Dari 50 bunga yang sebenarnya adalah Versicolor, 49 bunga diklasifikasikan dengan benar sebagai Versicolor, sementara 1 bunga salah diklasifikasikan sebagai Virginica. Ini memberikan tingkat akurasi klasifikasi sebesar 98.00% untuk spesies Versicolor.
- Virginica:
- Dari 50 bunga yang sebenarnya adalah Virginica, 49 bunga diklasifikasikan dengan benar sebagai Virginica, sementara 1 bunga salah diklasifikasikan sebagai Versicolor. Ini memberikan tingkat akurasi klasifikasi sebesar 98.00% untuk spesies Virginica.
Secara keseluruhan, model kita mengklasifikasikan 98.67% dari semua kasus dengan benar.
Klasifikasi Metrik Lainnya
- Recall (Sensitivitas atau TPR - True Positive Rate):
- Untuk Setosa, Versicolor, dan Virginica, recall menunjukkan persentase dari masing-masing spesies yang sebenarnya diklasifikasikan dengan benar oleh model kita. Recall 100.00% untuk Setosa berarti semua bunga Setosa sebenarnya diklasifikasikan dengan benar.
- Precision:
- Precision menunjukkan persentase dari prediksi model kita yang benar-benar tepat. Misalnya, precision 100.00% untuk Setosa berarti setiap kali model kita memprediksi bunga sebagai Setosa, prediksinya selalu benar.
- F1 Score:
- F1 Score adalah rata-rata harmonik dari recall dan precision. Skor ini memberikan gambaran keseluruhan tentang kinerja model kita dalam hal keseimbangan antara recall dan precision. Nilai yang lebih tinggi menunjukkan kinerja yang lebih baik.
Dari interpretasi di atas, kita dapat melihat bahwa model regresi multinomial kita memiliki kinerja yang sangat baik dalam mengklasifikasikan spesies bunga Iris berdasarkan prediktor yang ada.
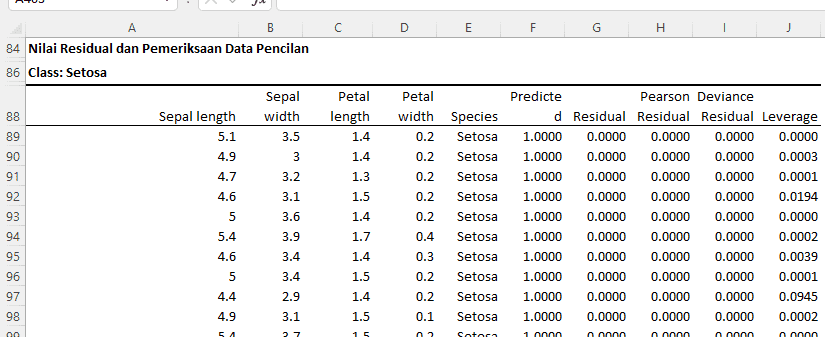
Tabel Residual
Class: Setosa
Class: Versicolor

Berikut interpretasikan untuk hasil analisis residual dan pemeriksaan data pencilan:
Class: Setosa
- Residual: Ini menunjukkan perbedaan antara nilai observasi aktual dan nilai yang diprediksi oleh model. Semua observasi memiliki residual 0, yang berarti model kita memprediksi spesies Setosa dengan sempurna untuk semua observasi ini.
- Pearson Residual: Ini adalah residual yang dinormalisasi berdasarkan variansi. Semua observasi, kecuali satu, memiliki Pearson residual mendekati 0, menunjukkan bahwa prediksi model kita sesuai dengan observasi.
- Deviance Residual: Ini memberikan ukuran seberapa baik model kita memprediksi setiap observasi individu. Semua observasi memiliki deviance residual mendekati 0, menunjukkan bahwa model kita memprediksi dengan baik.
- Leverage: Mengukur seberapa jauh nilai independen dari suatu observasi dari rata-rata. Observasi dengan leverage tinggi (seperti yang ditunjukkan oleh "Extrim") memiliki nilai prediktor yang tidak biasa atau ekstrem.
- Studentized Pearson Residual&Studentized Deviance Residual: Ini adalah residual yang telah dinormalisasi berdasarkan kesalahan standar. Nilai yang besar dari metrik ini dapat menunjukkan adanya outlier.
- Cooks Distance&DFITS: Kedua metrik ini memberikan ukuran pengaruh suatu observasi terhadap estimasi model. Observasi dengan nilai Cook's Distance atau DFITS yang tinggi dapat memiliki pengaruh yang tidak biasa pada model.
Class: Versicolor
- Untuk kelas ini, ada observasi dengan "Outlier" sebagai diagnosa. Ini berarti model kita memiliki kesulitan dalam memprediksi observasi ini dengan benar, dan nilai yang diprediksi oleh model jauh dari observasi aktual.
Diagnostik:
- Outlier: Observasi dengan residual yang besar dianggap sebagai outlier. Dalam konteks ini, observasi dengan "Outlier" sebagai diagnosa memiliki residual yang signifikan, menunjukkan bahwa model kita tidak memprediksi observasi ini dengan baik.
- Extrim: Observasi dengan nilai leverage yang tinggi dianggap sebagai ekstrem. Dalam konteks ini, observasi dengan "Extrim" sebagai diagnosa memiliki nilai prediktor yang tidak biasa atau ekstrem.
Dari interpretasi di atas, kita dapat melihat bahwa meskipun model kita memiliki kinerja yang baik untuk sebagian besar observasi, masih ada beberapa observasi yang model kita kesulitan dalam memprediksinya dengan benar.
Kesimpulan
Berdasarkan hasil analisis, berikut kesimpulannya:
- Model Regresi: Model regresi multinomial telah dikembangkan untuk memprediksi spesies bunga Iris berdasarkan empat prediktor: panjang sepal, lebar sepal, panjang petal, dan lebar petal. Ada dua persamaan regresi yang diberikan, yaitu untuk Setosa dan Versicolor, dengan Virginica dianggap sebagai kategori referensi.
- Kinerja Model: Model menunjukkan kecocokan yang sangat baik dengan data, dengan koefisien determinasi (R2) sebesar 96.39%. Ini berarti bahwa 96.39% variasi dalam spesies dapat dijelaskan oleh model regresi kita.
- Kebaikansuai Regresi: Berbagai metrik, seperti Cox-Snell R2, Nagelkerke R2, AIC, BIC, dan Log Likelihood, semuanya mengonfirmasi bahwa model regresi multinomial kita memiliki kecocokan yang baik dengan data.
- Estimasi Koefisien: Beberapa koefisien signifikan pada taraf nyata 5% atau 1%, menunjukkan bahwa prediktor tertentu memiliki pengaruh signifikan dalam memprediksi spesies bunga Iris. Namun, ada juga beberapa koefisien yang tidak signifikan, menunjukkan bahwa efeknya mungkin tidak signifikan dalam konteks model ini.
- Klasifikasi: Model kita berhasil mengklasifikasikan 98.67% dari semua kasus dengan benar, menunjukkan efektivitas yang sangat baik dalam klasifikasi spesies bunga Iris berdasarkan prediktor yang diberikan.
- Residual dan Diagnostik Pencilan: Meskipun model kita memiliki kinerja yang baik untuk sebagian besar observasi, masih ada beberapa observasi yang model kita kesulitan dalam memprediksinya dengan benar, seperti yang ditunjukkan oleh beberapa nilai residual yang signifikan dan diagnosis 'Outlier' dan 'Extrim'.
Dengan demikian, berdasarkan analisis yang dilakukan, model regresi multinomial yang dikembangkan menunjukkan kinerja yang sangat baik dalam memprediksi spesies bunga Iris berdasarkan karakteristik botaninya. Model ini dapat diandalkan untuk klasifikasi spesies bunga Iris di masa mendatang, dengan mempertimbangkan potensi outlier atau observasi ekstrem yang mungkin mempengaruhi prediksi.
Penulisan dalam Laporan Karya Ilmiah
Analisis Regresi Multinomial
Dengan menggunakan analisis regresi multinomial, model prediksi untuk spesies bunga Iris berhasil dikembangkan. Model ini melibatkan empat variabel prediktor, yaitu panjang sepal, lebar sepal, panjang petal, dan lebar petal. Dari analisis, ditemukan bahwa model memiliki kecocokan yang baik dengan data, ditunjukkan oleh koefisien determinasi (R2) sebesar 96.39%.
Kinerja Model
Berdasarkan tabel klasifikasi, model berhasil mengklasifikasikan 98.67% dari semua kasus dengan benar. Hal ini menunjukkan bahwa model memiliki efektivitas yang sangat baik dalam klasifikasi spesies bunga Iris.
Diagnostik Pencilan
Walaupun model menunjukkan kinerja yang baik, terdapat beberapa observasi dimana model kesulitan dalam memprediksinya dengan benar. Hal ini ditandai dengan beberapa nilai residual yang signifikan serta observasi yang diberi label 'Outlier' atau 'Extrim'.
Kesimpulan
Berdasarkan analisis regresi multinomial yang dilakukan pada dataset bunga Iris, ditemukan bahwa empat karakteristik botani, yaitu panjang sepal, lebar sepal, panjang petal, dan lebar petal, memiliki pengaruh signifikan dalam memprediksi spesies bunga Iris. Model yang dikembangkan menunjukkan kecocokan yang sangat baik dengan data, dengan kemampuan mengklasifikasikan spesies bunga dengan akurasi sebesar 98.67%. Meskipun demikian, terdapat beberapa observasi dimana model kesulitan dalam memprediksinya dengan benar, yang ditandai sebagai outlier atau ekstrem.